在 Flink 1.12 中,Flink on Kubernetes 的 Native 部署方案由实验特性正式变更为生产环境可用。其中一个重要特性是扩展了 HA 的实现,引入了一种新的、完全基于 Kubernetes 的 HA 方案。在此之前,Flink on Kubernetes 部署时如果需要开启 HA,需要依赖 ZooKeeper 来实现。在有了基于 Kubernetes 的 HA 方案后,不需要单独维护 ZooKeeper 集群,这样显然方便了不少。
JobManager HA 机制
HA,即高可用,主要是为了解决分布式系统中组件的单点失败(single point of failure)的问题。在一个 Flink 集群中,JobManager 负责协调各个组件,承担了任务调度和资源管理的主要的作用。默认情况下,一个 Flink 集群中只有一个 JobManager,一旦 JobManager 因为某种原因宕掉,那么集群中所有运行的任务都将失败。如果开启了 HA,那么将会有一个新的 JobManager 接管之前的 JobManager 的工作,从而避免任务失败的情况。
为了实现 JobManager 的 HA,需要几个服务的配合,即:
- 选举服务:从多个候选者中选出一个 Leader
- 服务发现:获取当前 Leader 的地址
- 状态保存:恢复作业运行时需要的一些状态(JobGraphs, user code jars, completed checkpoints),这个一般需要借助共享存储(如 HDFS,S3)完成
服务抽象
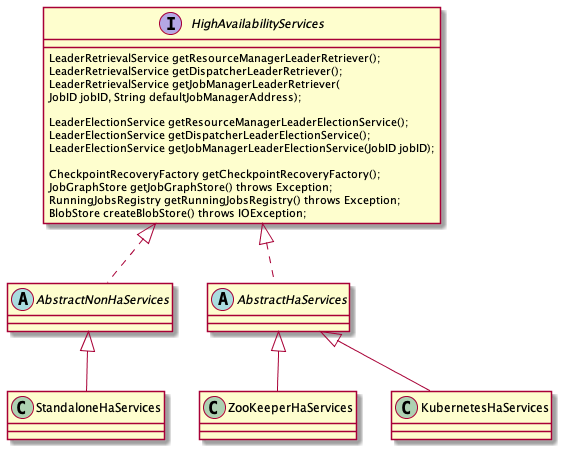
在 Flink 中,HA 依赖的服务被封装在 HighAvailabilityServices 中,这里面涉及到的一些关键组件包括:
- LeaderElectionService
- 有四个组件需要用到选举服务:
Dispatcher,ResourceManager,JobManager(每个作业有一个),RestEndpoint
- LeaderRetrievalService
- 获取各个服务的地址,例如 Client 提交作业时需要获取
RestEndpoint,TaskManager 获取 ResourceManager 地址用于注册、提供计算资源等
- RunningJobsRegistry
- JobGraphStore
- BlobStore
- CheckpointRecoveryFactory
CompletedCheckpointStore,存储已经完成的 Checkpoint 的元数据信息CheckpointIDCounter,生成 checkpoint id
选举服务
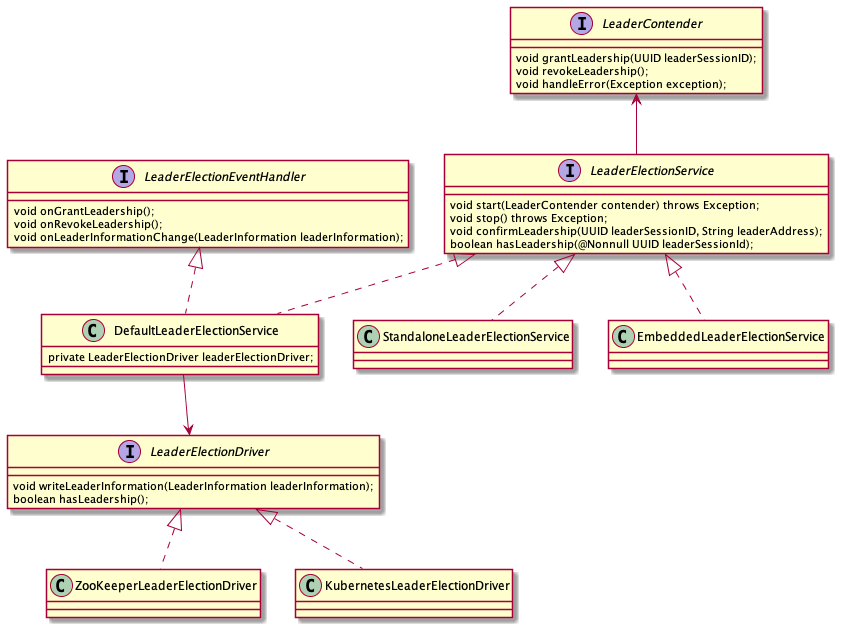
Leader 选举主要依赖 LeaderElectionService(选举服务)和 LeaderContender(参与竞选的对象)共同来完成。
LeaderContender 是具体的需要进行选举的组件,例如 ResourceManager, DispatcherRunner,JobManagerRunner 等。当一个 LeaderContender 竞选成功后,会通过 LeaderContender#grantLeadership(UUID leaderSessionId) 得到通知。
每一个 LeaderContender 都会有一个关联的 LeaderElectionService 对象。在成功竞选为 Leader 后,LeaderElectionService 会生成一个 leaderSessionId,这个 id 作为此次选举成功的唯一标识告知 LeaderContender,一旦 LeaderContender 确认自己的 leader 角色后,会调用 LeaderElectionService#confirmLeadership(UUID leaderSessionID, String leaderAddress) 来发布自己的地址。
对于选举服务的具体实现,一般是借助一种分布式协调系统,比如 ZooKeeper,Etcd 等来完成,或者也可以自己实现分布式一致性算法。在 Flink 中,把选举服务的具体实现留在 LeaderElectionDriver 接口中,有基于 ZooKeeper 的实现 ZooKeeperLeaderElectionDriver,也有基于 Kubernetes ConfigMap (底层基于 Etcd) 的实现 KubernetesLeaderElectionDriver。
服务发现
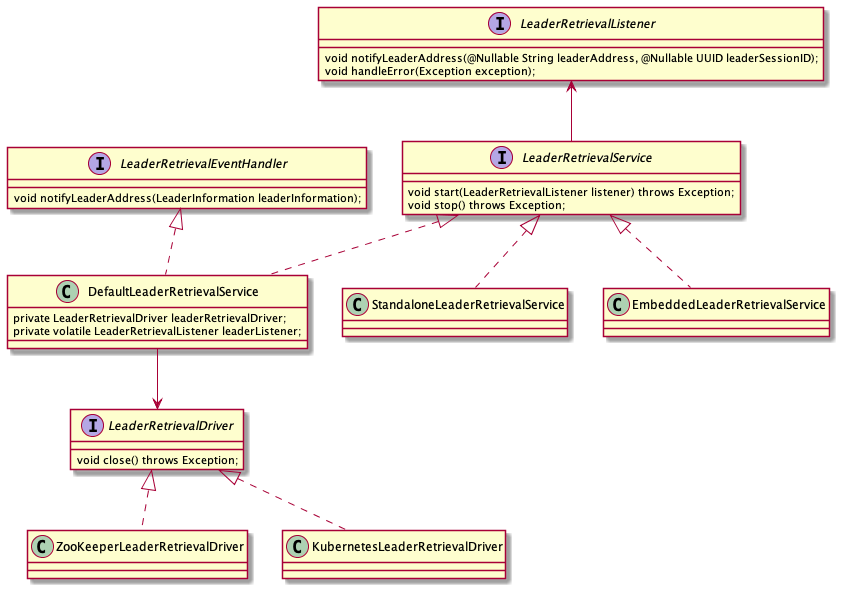
服务发现的主要目的是获取各个服务组件的 Leader 地址,其实现主要是依赖 LeaderRetrievalService 和 LeaderRetrievalListner 这两个接口。LeaderRetriverService 可以启动一个对 Leader 地址的监听,并通知 LeaderRetrievalListner。
在 HA 模式下,LeaderRetrievalService 的具体实现是 DefaultLeaderRetrievalService。服务发现和选举是伴生的,前面说过,选举完成后会发布 Leader 地址,所谓发布,就是要把地址信息放在一个共享存储中,例如 ZokKeeper 的节点,或者 Kubernetes ConfigMap 中,对应的地址获取逻辑见 ZooKeeperLeaderRetrievalDriver 和 KubernetesLeaderRetrievalDriver。
状态保存
状态保存的目的是在 Leader 发生切换后,新的 Leader 能够获取到旧的 Leader 保存的状态数据。这里保存的数据分为两类,一种是比较轻量级的数据,例如在 RunningJobsRegistry 中存储的任务运行状态,另一种存储的数据量可能比较大,例如 JobGraph,用户提供的 Jar 文件,CompletedCheckpointStore 中存储的 CompletedCheckpoint。对于第一类数据,直接借助 ZooKeeper 或者 Kubernetes 的存储能力即可满足要求;而对于后一种数据,则一般采取将数据存在共享文件系统,然后将文件系统路径存储在 ZooKeeper 或者 Kubernetes ConfigMap 中。
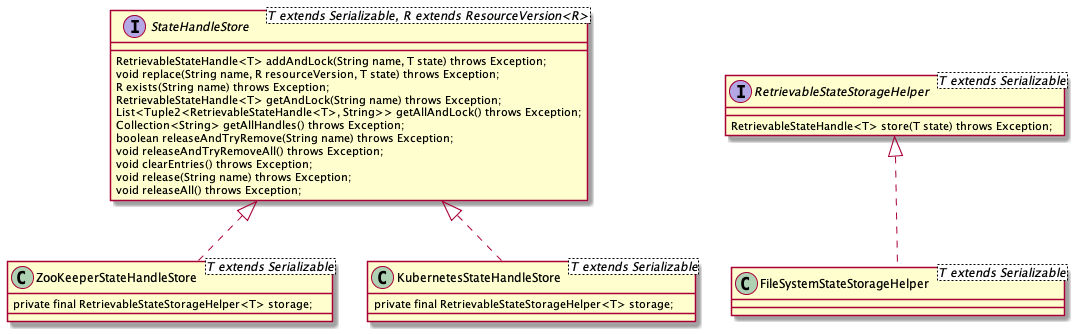
状态存储的主要逻辑参考 StateHandleStore 和 RetrievableStateStorageHelper。
基于 ZooKeeper 的 HA 实现
基于 ZooKeeper 的选举和服务发现是分布式系统中比较常见的技术选型了。所有参加选举的候选者都尝试去 ZooKeeper 中创建一个临时节点,最先创建成功的成为 Leader。临时节点在会话断开后被自动删除,其它 follower 可监听该临时节点,在节点删除后获得通知,重新参与竞选。
我们一般不会直接使用原生的 API 操作 ZooKeeper。Netflex 开源的 Apache Curator 框架封装了对连接管理、会话失效等一些异常问题的处理
,而且提供了一些常见的诸如选举、分布式锁等常用算法的实现,是目前使用 ZooKeeper 的主流方式。Flink 中对 ZooKeeper 的操作也是借助 Curator 完成的。
Leader 选举
Flink 使用 ZK 进行 Leader 选举的主要逻辑在 ZooKeeperLeaderElectionDriver 中,不同组件的实现是一样的,只是用来进行选举的 ZK 路径不一样。
Curator 中 LeaderLatch 封装了 Leader 选举的基本逻辑,LeaderLatch 接受一个回调对象 LeaderLatchListener,在选举成功后会得到回调通知。
ZooKeeperLeaderElectionDriver 同样通过 NodeCache 实现了对 Leader 地址节点的监听,在节点信息发生变化时会得到回调,这个主要是为了让 Leader 节点修正 ZK 中保存的 Leader 信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
public class ZooKeeperLeaderElectionDriver
implements LeaderElectionDriver,
LeaderLatchListener,
NodeCacheListener,
UnhandledErrorListener {
/** Curator recipe for leader election. */
private final LeaderLatch leaderLatch;
/** Curator recipe to watch a given ZooKeeper node for changes. */
private final NodeCache cache;
/** ZooKeeper path of the node which stores the current leader information. */
private final String leaderPath;
public ZooKeeperLeaderElectionDriver(
CuratorFramework client,
String latchPath,
String leaderPath,
LeaderElectionEventHandler leaderElectionEventHandler,
FatalErrorHandler fatalErrorHandler,
String leaderContenderDescription)
throws Exception {
leaderLatch = new LeaderLatch(client, checkNotNull(latchPath));
cache = new NodeCache(client, leaderPath);
client.getUnhandledErrorListenable().addListener(this);
running = true;
// 选举
leaderLatch.addListener(this);
leaderLatch.start();
// 监听节点变化
cache.getListenable().addListener(this);
cache.start();
client.getConnectionStateListenable().addListener(listener);
}
}
|
在选举完成后,会将 Leader 信息写入 ZK 的节点中,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
public class ZooKeeperLeaderElectionDriver {
/** Writes the current leader's address as well the given leader session ID to ZooKeeper. */
@Override
public void writeLeaderInformation(LeaderInformation leaderInformation) {
//...
try {
// ...
boolean dataWritten = false;
while (!dataWritten && leaderLatch.hasLeadership()) {
Stat stat = client.checkExists().forPath(leaderPath);
if (stat != null) {
long owner = stat.getEphemeralOwner();
long sessionID = client.getZookeeperClient().getZooKeeper().getSessionId();
if (owner == sessionID) {
try {
client.setData().forPath(leaderPath, baos.toByteArray());
dataWritten = true;
} catch (KeeperException.NoNodeException noNode) {
// node was deleted in the meantime
}
} else {
try {
client.delete().forPath(leaderPath);
} catch (KeeperException.NoNodeException noNode) {
// node was deleted in the meantime --> try again
}
}
} else {
try {
client.create().creatingParentsIfNeeded()
.withMode(CreateMode.EPHEMERAL)
.forPath(leaderPath, baos.toByteArray());
dataWritten = true;
} catch (KeeperException.NodeExistsException nodeExists) {
// node has been created in the meantime --> try again
}
}
}
} catch (Exception e) {
}
}
}
|
服务发现
获取 Leader 地址的逻辑比较简单,就是监听 ZooKeeper 节点的数据变化,从节点中取出 Leader 选举完成后写入的信息。主要的逻辑就是借助 NodeCache 来完成的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
class ZooKeeperLeaderRetrievalDriver
implements LeaderRetrievalDriver, NodeCacheListener, UnhandledErrorListener {
public ZooKeeperLeaderRetrievalDriver(
CuratorFramework client,
String retrievalPath,
LeaderRetrievalEventHandler leaderRetrievalEventHandler,
FatalErrorHandler fatalErrorHandler)
throws Exception {
this.cache = new NodeCache(client, retrievalPath);
client.getUnhandledErrorListenable().addListener(this);
cache.getListenable().addListener(this);
cache.start();
client.getConnectionStateListenable().addListener(connectionStateListener);
running = true;
}
@Override
public void nodeChanged() {
retrieveLeaderInformationFromZooKeeper();
}
private void retrieveLeaderInformationFromZooKeeper() {
try {
final ChildData childData = cache.getCurrentData();
if (childData != null) {
final byte[] data = childData.getData();
if (data != null && data.length > 0) {
ByteArrayInputStream bais = new ByteArrayInputStream(data);
ObjectInputStream ois = new ObjectInputStream(bais);
final String leaderAddress = ois.readUTF();
final UUID leaderSessionID = (UUID) ois.readObject();
leaderRetrievalEventHandler.notifyLeaderAddress(
LeaderInformation.known(leaderSessionID, leaderAddress));
return;
}
}
leaderRetrievalEventHandler.notifyLeaderAddress(LeaderInformation.empty());
} catch (Exception e) {
}
}
}
|
状态保存
对于比较轻量的状态,如作业运行状态,直接基于固定的 ZK 路径进行读写即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
public class KubernetesRunningJobsRegistry implements RunningJobsRegistry {
@Override
public void setJobRunning(JobID jobID) throws IOException {
writeJobStatusToConfigMap(jobID, JobSchedulingStatus.RUNNING);
}
private void writeJobStatusToConfigMap(JobID jobID, JobSchedulingStatus status)
throws IOException {
final String key = getKeyForJobId(jobID);
try {
kubeClient.checkAndUpdateConfigMap(
configMapName,
configMap -> {
if (KubernetesLeaderElector.hasLeadership(configMap, lockIdentity)) {
final Optional<JobSchedulingStatus> optional = getJobStatus(configMap, jobID);
if (!optional.isPresent() || optional.get() != status) {
configMap.getData().put(key, status.name());
return Optional.of(configMap);
}
}
return Optional.empty();
})
.get();
} catch (Exception e) {
}
}
}
|
对于数据量比较大的状态,如 JobGraph,CompletedCheckpoint,则先写入共享文件系统,然后将文件路径保存的 ZK 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
public class ZooKeeperStateHandleStore<T extends Serializable>
implements StateHandleStore<T, IntegerResourceVersion> {
@Override
public RetrievableStateHandle<T> addAndLock(String pathInZooKeeper, T state) throws Exception {
final String path = normalizePath(pathInZooKeeper);
// 写入外部存储
RetrievableStateHandle<T> storeHandle = storage.store(state);
// 将路径等元信息写入 ZK
boolean success = false;
try {
// Serialize the state handle. This writes the state to the backend.
byte[] serializedStoreHandle = InstantiationUtil.serializeObject(storeHandle);
// Write state handle (not the actual state) to ZooKeeper. This is expected to be
// smaller than the state itself. This level of indirection makes sure that data in
// ZooKeeper is small, because ZooKeeper is designed for data in the KB range, but
// the state can be larger.
// Create the lock node in a transaction with the actual state node. That way we can
// prevent
// race conditions with a concurrent delete operation.
client.inTransaction()
.create()
.withMode(CreateMode.PERSISTENT)
.forPath(path, serializedStoreHandle)
.and()
.create()
.withMode(CreateMode.EPHEMERAL)
.forPath(getLockPath(path))
.and()
.commit();
success = true;
return storeHandle;
} catch (KeeperException.NodeExistsException e) {
// We wrap the exception here so that it could be caught in DefaultJobGraphStore
throw new AlreadyExistException("ZooKeeper node " + path + " already exists.", e);
} finally {
if (!success) {
// Cleanup the state handle if it was not written to ZooKeeper.
if (storeHandle != null) {
storeHandle.discardState();
}
}
}
}
}
|
CheckpointIDCount
在 Flink 触发 Checkpoint 的时候需要一个递增的 ID 生成器,这个在 ZK 中主要是借助 Curator 提供的分布式计数器 SharedCount 实现的。
1
2
3
4
5
6
7
8
9
10
11
|
public class ZooKeeperCheckpointIDCounter implements CheckpointIDCounter {
/** Curator recipe for shared counts. */
private final SharedCount sharedCount;
public ZooKeeperCheckpointIDCounter(
CuratorFramework client,
String counterPath,
LastStateConnectionStateListener connectionStateListener) {
this.sharedCount = new SharedCount(client, counterPath, 1);
}
}
|
基于 Kubernetes 的 HA 实现
Kubernetes 官方在Simple leader election with Kubernetes and Docker这篇文章中描述了如何基于 Kubernetes 来实现一个 Leader 选举服务。主要依赖 Kubernetes 的两个特性:
- ResourceVersions: 每一个 API Object 都有一个唯一的资源版本,可以基于这个特性实现 CAS 操作
- Annotations: 每一个 API Object 可以被标注上一组 key/value 属性,用来保存一些元数据
Kubernetes 官方的 Java API 提供了 Leader 选举服务的具体实现,Flink 使用的 Fabric8io kubernetes-client 也有相应的实现。
在 Kubernetes 中,ConfigMap 可以当作轻量的键值存储使用,因此可以用来保存一些元数据信息,类似于 ZooKeeper 中用 ZNode 节点来保存元数据。
Flink 内部还基于 ResourceVersions 封装了一个对 ConfigMap 的 CAS 操作,以保证原子性,具体的逻辑见 FlinkKubeClient#checkAndUpdateConfigMap(String configMapName, Function<KubernetesConfigMap, Optional<KubernetesConfigMap>> function)。
Leader 选举
Flink 基于 Kubernetes 实现选举服务的主要逻辑在 KubernetesLeaderElectionDriver 中。由于 Kubernetes-client 的 LeaderElector#run() 是一个阻塞操作,Flink 提供了一个 KubernetesLeaderElector 将封装在 Executor 中变为一个非阻塞操作。LeaderElector 会尝试创建相应的 leader ConfigMap,每一个 KubernetesLeaderElectionDriver 会生成一个唯一的标识,这个标识在选举时会写入 config map 的 annotation 中,后面用来识别当前对象是否 leader。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
public class KubernetesLeaderElector {
public KubernetesLeaderElector(
NamespacedKubernetesClient kubernetesClient,
KubernetesLeaderElectionConfiguration leaderConfig,
LeaderCallbackHandler leaderCallbackHandler) {
final LeaderElectionConfig leaderElectionConfig =
new LeaderElectionConfigBuilder()
.withName(leaderConfig.getConfigMapName())
.withLeaseDuration(leaderConfig.getLeaseDuration())
.withLock(
new ConfigMapLock(
kubernetesClient.getNamespace(),
leaderConfig.getConfigMapName(),
leaderConfig.getLockIdentity()) /*唯一标识*/)
.withRenewDeadline(leaderConfig.getRenewDeadline())
.withRetryPeriod(leaderConfig.getRetryPeriod())
.withLeaderCallbacks(
new LeaderCallbacks(
leaderCallbackHandler::isLeader, //回调
leaderCallbackHandler::notLeader, //回调
newLeader -> LOG.info("New leader elected {} for {}.", newLeader,leaderConfig.getConfigMapName())))
.build();
internalLeaderElector = new LeaderElector<>(kubernetesClient, leaderElectionConfig);
}
// 变为非阻塞操作
public void run() {
executorService.submit(internalLeaderElector::run);
}
public static boolean hasLeadership(KubernetesConfigMap configMap, String lockIdentity) {
final String leader = configMap.getAnnotations().get(LEADER_ANNOTATION_KEY);
return leader != null && leader.contains(lockIdentity);
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
public class KubernetesLeaderElectionDriver implements LeaderElectionDriver {
private final String configMapName; // 用于 leader 选举、发布 leader 地址的 config map
private final String lockIdentity; // 唯一标识,用于识别是否 leader
public KubernetesLeaderElectionDriver(
FlinkKubeClient kubeClient,
KubernetesLeaderElectionConfiguration leaderConfig,
LeaderElectionEventHandler leaderElectionEventHandler,
FatalErrorHandler fatalErrorHandler) {
this.kubeClient = checkNotNull(kubeClient, "Kubernetes client");
checkNotNull(leaderConfig, "Leader election configuration");
this.leaderElectionEventHandler =
checkNotNull(leaderElectionEventHandler, "LeaderElectionEventHandler");
this.fatalErrorHandler = checkNotNull(fatalErrorHandler);
this.configMapName = leaderConfig.getConfigMapName();
this.lockIdentity = leaderConfig.getLockIdentity();
this.leaderElector = kubeClient.createLeaderElector(leaderConfig, new LeaderCallbackHandlerImpl());
this.configMapLabels =
KubernetesUtils.getConfigMapLabels(
leaderConfig.getClusterId(), LABEL_CONFIGMAP_TYPE_HIGH_AVAILABILITY);
running = true;
leaderElector.run();
// 监听 config map 变化
kubernetesWatch = kubeClient.watchConfigMaps(configMapName, new ConfigMapCallbackHandlerImpl());
}
}
|
在选举完成后,会将 Leader 信息写入对应的 ConfigMap 中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
public class KubernetesLeaderElectionDriver implements LeaderElectionDriver {
@Override
public void writeLeaderInformation(LeaderInformation leaderInformation) {
assert (running);
final UUID confirmedLeaderSessionID = leaderInformation.getLeaderSessionID();
final String confirmedLeaderAddress = leaderInformation.getLeaderAddress();
try {
kubeClient.checkAndUpdateConfigMap( // 封装的 CAS 操作,基于 ResourceVersion
configMapName,
configMap -> {
if (KubernetesLeaderElector.hasLeadership(configMap, lockIdentity)) {
// Get the updated ConfigMap with new leader information
if (confirmedLeaderAddress == null) {
configMap.getData().remove(LEADER_ADDRESS_KEY);
} else {
configMap.getData().put(LEADER_ADDRESS_KEY, confirmedLeaderAddress);
}
if (confirmedLeaderSessionID == null) {
configMap.getData().remove(LEADER_SESSION_ID_KEY);
} else {
configMap.getData().put(LEADER_SESSION_ID_KEY, confirmedLeaderSessionID.toString());
}
configMap.getLabels().putAll(configMapLabels);
return Optional.of(configMap);
}
return Optional.empty();
}).get();
} catch (Exception e) {
}
}
}
|
服务发现
Leader 的地址信息写入了 ConfigMap 中,因此直接从 ConfigMap 中直接取出响应的信息即可。 Kubernetes client 也支持在 ConfigMap 上设置监听器,监听 ConfigMap 的变更。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
public class KubernetesLeaderRetrievalDriver implements LeaderRetrievalDriver {
public KubernetesLeaderRetrievalDriver(
FlinkKubeClient kubeClient,
String configMapName,
LeaderRetrievalEventHandler leaderRetrievalEventHandler,
FatalErrorHandler fatalErrorHandler) {
this.kubeClient = checkNotNull(kubeClient, "Kubernetes client");
this.configMapName = checkNotNull(configMapName, "ConfigMap name");
this.leaderRetrievalEventHandler =
checkNotNull(leaderRetrievalEventHandler, "LeaderRetrievalEventHandler");
this.fatalErrorHandler = checkNotNull(fatalErrorHandler);
kubernetesWatch = kubeClient.watchConfigMaps(configMapName, new ConfigMapCallbackHandlerImpl());
running = true;
}
private class ConfigMapCallbackHandlerImpl
implements FlinkKubeClient.WatchCallbackHandler<KubernetesConfigMap> {
@Override
public void onModified(List<KubernetesConfigMap> configMaps) {
final KubernetesConfigMap configMap = checkConfigMaps(configMaps, configMapName);
leaderRetrievalEventHandler.notifyLeaderAddress(getLeaderInformationFromConfigMap(configMap));
}
}
}
|
状态保存
和 ZooKeeper 一样,Kubernetes 的 ConfigMap 只保存轻量的数据,对于一些比较大的数据,先写入外部文件系统,然后将元数据写入 ConfigMap 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public class KubernetesRunningJobsRegistry implements RunningJobsRegistry {
@Override
public void setJobRunning(JobID jobID) throws IOException {
writeJobStatusToConfigMap(jobID, JobSchedulingStatus.RUNNING);
}
private void writeJobStatusToConfigMap(JobID jobID, JobSchedulingStatus status) throws IOException {
final String key = getKeyForJobId(jobID);
try {
kubeClient.checkAndUpdateConfigMap(
configMapName,
configMap -> {
if (KubernetesLeaderElector.hasLeadership(configMap, lockIdentity)) {
final Optional<JobSchedulingStatus> optional = getJobStatus(configMap, jobID);
if (!optional.isPresent() || optional.get() != status) {
configMap.getData().put(key, status.name());
return Optional.of(configMap);
}
}
return Optional.empty();
}).get();
} catch (Exception e) {
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
public class KubernetesStateHandleStore<T extends Serializable>
implements StateHandleStore<T, StringResourceVersion> {
@Override
public RetrievableStateHandle<T> addAndLock(String key, T state) throws Exception {
// 写入外部文件系统
final RetrievableStateHandle<T> storeHandle = storage.store(state);
boolean success = false;
try {
final byte[] serializedStoreHandle = InstantiationUtil.serializeObject(storeHandle);
success =
kubeClient.checkAndUpdateConfigMap(
configMapName,
c -> {
if (KubernetesLeaderElector.hasLeadership(c, lockIdentity)) {
if (!c.getData().containsKey(key)) {
c.getData().put(key, encodeStateHandle(serializedStoreHandle));
return Optional.of(c);
} else {
throw new CompletionException(etKeyAlreadyExistException(key));
}
}
return Optional.empty();
})
.get();
return storeHandle;
} catch (Exception ex) {
throw ExceptionUtils.findThrowable(ex, AlreadyExistException.class)
.orElseThrow(() -> ex);
} finally {
if (!success) {
// Cleanup the state handle if it was not written to ConfigMap.
if (storeHandle != null) {
storeHandle.discardState();
}
}
}
}
}
|
CheckpointIDCount
CheckpointID 在 Kubernetes 中也是保存在 ConfigMap 中的,借助 CAS 更新实现原子操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public class KubernetesCheckpointIDCounter implements CheckpointIDCounter {
@Override
public long getAndIncrement() throws Exception {
final AtomicLong current = new AtomicLong();
final boolean updated =
kubeClient.checkAndUpdateConfigMap(
configMapName,
configMap -> {
if (KubernetesLeaderElector.hasLeadership(configMap, lockIdentity)) {
final long currentValue = getCurrentCounter(configMap);
current.set(currentValue);
configMap.getData().put(CHECKPOINT_COUNTER_KEY, String.valueOf(currentValue + 1));
return Optional.of(configMap);
}
return Optional.empty();
}).get();
if (updated) {
return current.get();
} else {
}
}
}
|
小结
总的来说,通过 Leader 选举、服务发现、状态存储这几个服务,在 Flink 中可以方便地对 HA 的底层实现进行扩展。Flink 提供的基于 Kubernetes 的 HA 实现可以简化 Flink on Kubernetes 的部署方式。
参考