流式数据处理中,很多操作要依赖于时间属性进行,因此时间属性也是流式引擎能够保证准确处理数据的基石。在这篇文章中,我们将对 Flink 中时间属性和窗口的实现逻辑进行分析。
概览
Google 2015 年发表的 The Dataflow Model 论文是流式处理领域非常具有指导意义的一篇论文,对于大规模/无边界/乱序数据集的数据特征和计算范式进行了总结,并且提出了一个通用的计算模型来指导流式数据处理系统的构建。Flink 参考了很多 Dataflow Model 的思想,尤其是在时间属性和窗口的设计实现方面。
Dataflow 模型将数据处理处理要处理的问题抽象为以下几个基本问题:
- What results are being computed?
- Where in event time they are being computed?
- When in processing time they are materialized?
- How earlier results relate to later refinements?
要回答上面 Where 和 When 的问题,就需要依赖于时间域(time domain),水位线(watermark),窗口模型(windowing model),触发器(triggering model)等机制。
Event Time vs Processing Time
在处理无边界的乱序数据时,需要对涉及到的时间域有一个清晰的认识。在流式处理系统,我们主要关注两种典型的时间属性:
- Event Time:事件发生时的确切时间
- Processing Time:事件在系统中被处理的时间
事件时间是一个消息的固有属性,消息在流处理系统中流转,事件时间始终保持不变;而处理时间则依赖于流处理系统的本地时钟,随着消息的流转,处理时间也在不断发生变动。在完全理想的情况下,事件事件和处理时间是一致的,也就是事件发生的时候就立即被处理。然而实际情况肯定并非如此,在分布式系统中,由于网络延迟等因素,处理时间必然落后于事件时间。
除了 Event Time 和 Processing Time 之外,Flink 还提供了 Ingestion Time(摄入时间)。摄入时间指的是一个消息进入 Flink 的时间,随着消息的流转,摄入时间不会发生变动。并且,和事件时间可能会出现乱序问题不同,摄入时间是递增的。摄入时间介于事件时间和处理时间之间,
Window
对于一个无边界的数据流,窗口(Window)可以沿着时间的边界将其切割成有边界的数据块(chunk)来进行处理。图中给出了三种主要类型的窗口的简单示例。
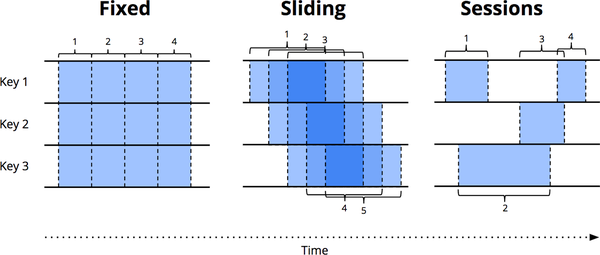
- Fixed windows(固定窗口):在 Flink 中被也称为 Tumbling windows(滚动窗口),将时间切割成具有固定时间长度的段。滚动窗口之间不会重叠。
- Sliding windows(滑动窗口):滑动窗口是滚动窗口更一般化的表现的形式,由窗口大小和滑动间隔这两个属性来定义。如果滑动间隔小于窗口大小,那么不同的窗口之间就会存在重叠;如果滑动间隔大于窗口大小,不同窗口之间就会存在间隔;如果滑动间隔等于窗口大小,就相当于滚动窗口。
- Session Windows(会话窗口):和滚动窗口与滑动窗口不同的是,会话窗口并没有固定的窗口大小;它是一种动态窗口,通常由超时间隔(timeout gap)来定义。当超过一段时间没有新的事件到达,则可以认为窗口关闭了。
Trigger
触发器(Trigger)提供了一种灵活的机制来决定窗口的计算结果在什么时候对外输出。理论上来说,只有两种类型的触发器,大部分的应用都是选择其一或组合使用:
- Repeated update triggers:重复更新窗口的计算结果,更新可以是由新消息到达时触发,也可以是每个一段时间(如1分钟)进行触发
- Completeness triggers:在窗口结束时进行触发,这是更符合直觉的使用方法,也和批处理模式的计算结果相吻合。但是需要一种机制来衡量一个窗口的所有消息都已经被正确地处理了。
Watermark
怎么确定一个窗口是否已经结束,这在流式数据处理系统中并非一个很容易解决的问题。如果窗口是基于处理时间的,那么问题确实容易解决,因为处理时间是完全基于本地时钟的;但是如果窗口基于事件时间,由于分布式系统中消息可能存在延迟、乱序到达的问题,即便系统已经接收到窗口边界以外的数据了,也不能确定前面的所有数据都已经到达了。水位线(Watermark)机制就是用于解决这个问题的。
Watermark 是事件时间域中衡量输入完成进度的一种时间概念。换句话说,在处理使用事件时间属性的数据流时,Watermark 是系统测量数据处理进度的一种方法。假如当前系统的 watermark 为时间 T,那么系统认为所有事件时间小于 T 的消息都已经到达,即系统任务它不会再接收到事件时间小于 T 的消息了。有了 Watermark,系统就可以确定使用事件时间的窗口是否已经完成。但是 Watermark 只是一种度量指标,系统借由它来评估当前的进度,并不能完全保证不会出现小于当前 Watermark 的消息。对于这种消息,即“迟到”的消息,需要进行特殊的处理。这也就是前面所说的流处理系统面临的 How 的问题,即如何处理迟到的消息,从而修正已经输出的计算结果。
事件时间和水位线
Flink 内部使用 StreamRecord 来表示需要被处理的一条消息,使用 Watermark 来表示一个水位线的标记。Watermark 和 StreamRecord 一样,需要在上下游的算子之间进行流动,它们拥有共同的父类 StreamElement。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
//对实际的消息类型做一层封装,timestamp就是这条记录关联的事件时间
public final class StreamRecord<T> extends StreamElement {
/** The actual value held by this record. */
private T value;
/** The timestamp of the record. */
private long timestamp;
/** Flag whether the timestamp is actually set. */
private boolean hasTimestamp;
}
public final class Watermark extends StreamElement {
/** The watermark that signifies end-of-event-time. */
public static final Watermark MAX_WATERMARK = new Watermark(Long.MAX_VALUE);
/** The timestamp of the watermark in milliseconds. */
private final long timestamp;
}
|
有两种方式来生成一个消息流的 event time 和 watermark,一种方式是在数据源中直接生成,另一种方式是通过 Timestamp Assigners / Watermark Generators。
在 SourceFunction 中生成时间信息
在 SourceFunction 中,可以通过 SourceContext 接口提供的 SourceContext.collectWithTimestamp(T element, long timestamp) 提交带有时间戳的消息,通过 SourceContext.emitWatermark(Watermark mark) 提交 watermark。SourceContext 有几种不同的实现,根据时间属性的设置,会自动选择不同的 SourceContext。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
public class StreamSourceContexts {
/**
* Depending on the {@link TimeCharacteristic}, this method will return the adequate
* {@link org.apache.flink.streaming.api.functions.source.SourceFunction.SourceContext}. That is:
* <ul>
* <li>{@link TimeCharacteristic#IngestionTime} = {@code AutomaticWatermarkContext}</li>
* <li>{@link TimeCharacteristic#ProcessingTime} = {@code NonTimestampContext}</li>
* <li>{@link TimeCharacteristic#EventTime} = {@code ManualWatermarkContext}</li>
* </ul>
* */
public static <OUT> SourceFunction.SourceContext<OUT> getSourceContext(
TimeCharacteristic timeCharacteristic,
ProcessingTimeService processingTimeService,
Object checkpointLock,
StreamStatusMaintainer streamStatusMaintainer,
Output<StreamRecord<OUT>> output,
long watermarkInterval,
long idleTimeout) {
final SourceFunction.SourceContext<OUT> ctx;
switch (timeCharacteristic) {
case EventTime:
ctx = new ManualWatermarkContext<>(
output,
processingTimeService,
checkpointLock,
streamStatusMaintainer,
idleTimeout);
break;
case IngestionTime:
ctx = new AutomaticWatermarkContext<>(
output,
watermarkInterval,
processingTimeService,
checkpointLock,
streamStatusMaintainer,
idleTimeout);
break;
case ProcessingTime:
ctx = new NonTimestampContext<>(checkpointLock, output);
break;
default:
throw new IllegalArgumentException(String.valueOf(timeCharacteristic));
}
return ctx;
}
}
|
如果系统时间属性被设置为 TimeCharacteristic#ProcessingTime,那么 NonTimestampContext 会忽略掉时间戳和watermark;如果时间属性被设置为 TimeCharacteristic#EventTime,那么通过 ManualWatermarkContext 提交的 StreamRecord 就会包含时间戳,watermark 也会正常提交。比较特殊的是 TimeCharacteristic#IngestionTime,AutomaticWatermarkContext 会使用系统当前时间作为 StreamRecord 的时间戳,并定期提交 watermark,从而实现 IngestionTime 的效果。
Timestamp Assigners / Watermark Generators
也可以通过 Timestamp Assigners / Watermark Generators 来生成事件时间和 watermark,一般是从消息中提取出时间字段。通过 DataStream.assignTimestampsAndWatermarks(AssignerWithPeriodicWatermarks) 和 DataStream.assignTimestampsAndWatermarks(AssignerWithPunctuatedWatermarks) 方法和来自定义提取 timstamp 和生成 watermark 的逻辑。
AssignerWithPeriodicWatermarks 和 AssignerWithPunctuatedWatermarks 都继承了 TimestampAssigner 接口:
1
2
3
4
5
6
7
8
9
10
11
|
public interface TimestampAssigner<T> extends Function {
long extractTimestamp(T element, long previousElementTimestamp);
}
public interface AssignerWithPeriodicWatermarks<T> extends TimestampAssigner<T> {
@Nullable Watermark getCurrentWatermark();
}
public interface AssignerWithPunctuatedWatermarks<T> extends TimestampAssigner<T> {
@Nullable Watermark checkAndGetNextWatermark(T lastElement, long extractedTimestamp);
}
|
AssignerWithPeriodicWatermarks 和 AssignerWithPunctuatedWatermarks 的区别在于 watermark 的生成方式不一样。如果使用 AssignerWithPeriodicWatermarks 那么会定期生成 watermark 信息;而如果使用 AssignerWithPunctuatedWatermarks 则一般依赖于数据流中的特殊元素来生成 watermark。
在使用 AssignerWithPeriodicWatermarks 的情况下会生成一个 TimestampsAndPeriodicWatermarksOperator 算子,TimestampsAndPeriodicWatermarksOperator 会注册定时器,定期提交 watermark 到下游:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
public class TimestampsAndPeriodicWatermarksOperator<T>
extends AbstractUdfStreamOperator<T, AssignerWithPeriodicWatermarks<T>>
implements OneInputStreamOperator<T, T>, ProcessingTimeCallback {
@Override
public void open() throws Exception {
super.open();
currentWatermark = Long.MIN_VALUE;
watermarkInterval = getExecutionConfig().getAutoWatermarkInterval();
//注册一个定时器
if (watermarkInterval > 0) {
long now = getProcessingTimeService().getCurrentProcessingTime();
getProcessingTimeService().registerTimer(now + watermarkInterval, this);
}
}
@Override
public void processElement(StreamRecord<T> element) throws Exception {
//从元素中提取时间
final long newTimestamp = userFunction.extractTimestamp(element.getValue(),
element.hasTimestamp() ? element.getTimestamp() : Long.MIN_VALUE);
output.collect(element.replace(element.getValue(), newTimestamp));
}
//定时器触发的回调函数
@Override
public void onProcessingTime(long timestamp) throws Exception {
//watermark 大于当前值,则提交
Watermark newWatermark = userFunction.getCurrentWatermark();
if (newWatermark != null && newWatermark.getTimestamp() > currentWatermark) {
currentWatermark = newWatermark.getTimestamp();
// emit watermark
output.emitWatermark(newWatermark);
}
// register next timer
long now = getProcessingTimeService().getCurrentProcessingTime();
getProcessingTimeService().registerTimer(now + watermarkInterval, this);
}
}
|
在使用 AssignerWithPunctuatedWatermarks 的时候,会生成一个 TimestampsAndPunctuatedWatermarksOperator 算子,会针对每个元素判断是否需要提交 watermark:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
public class TimestampsAndPunctuatedWatermarksOperator<T>
extends AbstractUdfStreamOperator<T, AssignerWithPunctuatedWatermarks<T>>
implements OneInputStreamOperator<T, T> {
@Override
public void processElement(StreamRecord<T> element) throws Exception {
final T value = element.getValue();
//生成时间信息
final long newTimestamp = userFunction.extractTimestamp(value,
element.hasTimestamp() ? element.getTimestamp() : Long.MIN_VALUE);
output.collect(element.replace(element.getValue(), newTimestamp));
//判断是否需要提交 watermark
final Watermark nextWatermark = userFunction.checkAndGetNextWatermark(value, newTimestamp);
if (nextWatermark != null && nextWatermark.getTimestamp() > currentWatermark) {
currentWatermark = nextWatermark.getTimestamp();
output.emitWatermark(nextWatermark);
}
}
}
|
Timer 定时器
Timer 提供了一种定时触发器的功能,通过 TimerService 接口注册 timer,触发的回调被封装为 Triggerable:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public interface TimerService {
long currentProcessingTime();
long currentWatermark();
void registerProcessingTimeTimer(long time);
void registerEventTimeTimer(long time);
void deleteProcessingTimeTimer(long time);
void deleteEventTimeTimer(long time);
}
public interface Triggerable<K, N> {
void onEventTime(InternalTimer<K, N> timer) throws Exception;
void onProcessingTime(InternalTimer<K, N> timer) throws Exception;
}
|
TimerService 不仅提供了注册和取消 timer 的功能,还可以通过它来获取当前的系统时间和 watermark 的值。需要注意的一点是,Timer 只能在 KeyedStream 中使用。和 TimerService 相对应的是,Flink 内部使用 InternalTimerService,可以设置 timer 关联的 namespace 和 key。Timer 实际上是一种特殊的状态,在 checkpoint 时会写入快照中,这一点在前面分析 checkpoint 过程时也有介绍。
在 InternalTimeService 中注册的 timer 有两种类型,分别为基于系统时间的和基于事件时间的,它使用两个优先级队列分别保存这两种类型的 timer。Timer 则被抽象为接口 InternalTimer,每个 timer 有绑定的 key,namespace 和触发时间 timestamp,TimerHeapInternalTimer 是其具体实现。InternalTimerServiceImpl 内部的两个优先级队列会按照触发时间的大小进行排序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
public interface InternalTimer<K, N> extends PriorityComparable<InternalTimer<?, ?>>, Keyed<K> {
/** Function to extract the key from a {@link InternalTimer}. */
KeyExtractorFunction<InternalTimer<?, ?>> KEY_EXTRACTOR_FUNCTION = InternalTimer::getKey;
/** Function to compare instances of {@link InternalTimer}. */
PriorityComparator<InternalTimer<?, ?>> TIMER_COMPARATOR =
(left, right) -> Long.compare(left.getTimestamp(), right.getTimestamp());
// Returns the timestamp of the timer. This value determines the point in time when the timer will fire.
long getTimestamp();
// Returns the key that is bound to this timer.
@Nonnull @Override K getKey();
// Returns the namespace that is bound to this timer.
@Nonnull N getNamespace();
}
public class InternalTimerServiceImpl<K, N> implements InternalTimerService<N>, ProcessingTimeCallback {
/**
* Processing time timers that are currently in-flight.
*/
private final KeyGroupedInternalPriorityQueue<TimerHeapInternalTimer<K, N>> processingTimeTimersQueue;
/**
* Event time timers that are currently in-flight.
*/
private final KeyGroupedInternalPriorityQueue<TimerHeapInternalTimer<K, N>> eventTimeTimersQueue;
/**
* The local event time, as denoted by the last received
* {@link org.apache.flink.streaming.api.watermark.Watermark Watermark}.
*/
private long currentWatermark = Long.MIN_VALUE;
private Triggerable<K, N> triggerTarget;
}
|
Processing time timer 的触发依赖于 ProcessingTimeService,它负责所有基于系统时间的触发器的管理,内部使用 ScheduledThreadPoolExecutor 调度定时任务;当定时任务被触发时,ProcessingTimeCallback 的回调会被调用。实际上,InternalTimerServiceImpl 内部依赖了 ProcessingTimeService,并且 InternalTimerServiceImpl 实现了 ProcessingTimeCallback 接口。当注册一个 Processing time timer 的时候,会将 timer 加入优先级队列,并正确设置下一次 ProcessingTimeService 的触发时间;当 ProcessingTimeService 触发 InternalTimerServiceImpl.onProcessingTime() 回调后,会从优先级队列中取出所有符合条件的触发器,并调用 triggerTarget.onProcessingTime(timer)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
public class InternalTimerServiceImpl<K, N> implements InternalTimerService<N>, ProcessingTimeCallback {
private final ProcessingTimeService processingTimeService;
@Override
public void registerProcessingTimeTimer(N namespace, long time) {
InternalTimer<K, N> oldHead = processingTimeTimersQueue.peek();
if (processingTimeTimersQueue.add(new TimerHeapInternalTimer<>(time, (K) keyContext.getCurrentKey(), namespace))) {
long nextTriggerTime = oldHead != null ? oldHead.getTimestamp() : Long.MAX_VALUE;
// check if we need to re-schedule our timer to earlier
if (time < nextTriggerTime) { //如果新加入的timer触发时间早于下一次的触发时间,那么应该重新设置下一次触发时间
if (nextTimer != null) {
nextTimer.cancel(false);
}
nextTimer = processingTimeService.registerTimer(time, this);
}
}
}
@Override
public void onProcessingTime(long time) throws Exception {
// null out the timer in case the Triggerable calls registerProcessingTimeTimer()
// inside the callback.
nextTimer = null;
InternalTimer<K, N> timer;
while ((timer = processingTimeTimersQueue.peek()) != null && timer.getTimestamp() <= time) {
processingTimeTimersQueue.poll();
keyContext.setCurrentKey(timer.getKey());
triggerTarget.onProcessingTime(timer); // timer 关联的 triggerTarget.onProcessingTime 被调用
}
if (timer != null && nextTimer == null) {
//注册下一次的触发任务
nextTimer = processingTimeService.registerTimer(timer.getTimestamp(), this);
}
}
}
|
Event time timer 的触发则依赖于系统当前的 watermark。当注册一个 Processing time timer 的时候,会将对应的 timer 加入优先级队列中;而一旦 watermark 上升,InternalTimerServiceImpl.advanceWatermark() 方法就会被调用,这时会检查优先级队列中所有触发时间早于当前 watermark 值的 timer,并依次调用 triggerTarget.onEventTime(timer) 方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
public class InternalTimerServiceImpl<K, N> implements InternalTimerService<N>, ProcessingTimeCallback {
public void advanceWatermark(long time) throws Exception {
currentWatermark = time;
InternalTimer<K, N> timer;
while ((timer = eventTimeTimersQueue.peek()) != null && timer.getTimestamp() <= time) {
eventTimeTimersQueue.poll();
keyContext.setCurrentKey(timer.getKey());
triggerTarget.onEventTime(timer);
}
}
@Override
public void registerEventTimeTimer(N namespace, long time) {
eventTimeTimersQueue.add(new TimerHeapInternalTimer<>(time, (K) keyContext.getCurrentKey(), namespace));
}
}
|
AbstractStreamOperator 使用 InternalTimeServiceManager 管理所有的 InternalTimerService。在 InternalTimeServiceManager 内部,InternalTimerService 是和名称绑定的,AbstractStreamOperator 在获取 InternalTimerService 时必须指定名称,这样可以方便地将不同的触发对象 Triggerable 绑定到不同的 InternalTimerService 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
@Internal
public class InternalTimeServiceManager<K> {
//所有的 InternalTimerServiceImpl 和名称的映射关系
private final Map<String, InternalTimerServiceImpl<K, ?>> timerServices;
//获取 InternalTimerService, 必须指定名称
public <N> InternalTimerService<N> getInternalTimerService(
String name,
TimerSerializer<K, N> timerSerializer,
Triggerable<K, N> triggerable) {
InternalTimerServiceImpl<K, N> timerService = registerOrGetTimerService(name, timerSerializer);
timerService.startTimerService(
timerSerializer.getKeySerializer(),
timerSerializer.getNamespaceSerializer(),
triggerable);
return timerService;
}
public void advanceWatermark(Watermark watermark) throws Exception {
for (InternalTimerServiceImpl<?, ?> service : timerServices.values()) {
service.advanceWatermark(watermark.getTimestamp());
}
}
}
public abstract class AbstractStreamOperator<OUT>
implements StreamOperator<OUT>, SetupableStreamOperator<OUT>, Serializable {
protected transient InternalTimeServiceManager<?> timeServiceManager;
public <K, N> InternalTimerService<N> getInternalTimerService(
String name,
TypeSerializer<N> namespaceSerializer,
Triggerable<K, N> triggerable) {
checkTimerServiceInitialization();
// the following casting is to overcome type restrictions.
KeyedStateBackend<K> keyedStateBackend = getKeyedStateBackend();
TypeSerializer<K> keySerializer = keyedStateBackend.getKeySerializer();
InternalTimeServiceManager<K> keyedTimeServiceHandler = (InternalTimeServiceManager<K>) timeServiceManager;
TimerSerializer<K, N> timerSerializer = new TimerSerializer<>(keySerializer, namespaceSerializer);
return keyedTimeServiceHandler.getInternalTimerService(name, timerSerializer, triggerable);
}
//处理 watermark
public void processWatermark(Watermark mark) throws Exception {
if (timeServiceManager != null) {
timeServiceManager.advanceWatermark(mark);
}
output.emitWatermark(mark);
}
}
|
所有的 operator 的实现都可以通过 InternalTimeServiceManager 来管理 InternalTimerService,那么在用户提供的算子计算逻辑中又如何使用 timer 呢?以 KeyedProcessOperator 和 KeyedProcessFunction 为例,不同类型的 operator 的实现逻辑基本类似,但要注意的一点是,timer 必须在 keyed stream 中才能使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
public abstract class KeyedProcessFunction<K, I, O> extends AbstractRichFunction {
private static final long serialVersionUID = 1L;
public abstract void processElement(I value, Context ctx, Collector<O> out) throws Exception;
//timer 触发的回调, OnTimerContext 是触发的上下文信息
public void onTimer(long timestamp, OnTimerContext ctx, Collector<O> out) throws Exception {}
/**
* Information available in an invocation of {@link #processElement(Object, Context, Collector)}
* or {@link #onTimer(long, OnTimerContext, Collector)}.
*/
public abstract class Context {
public abstract Long timestamp();
public abstract TimerService timerService(); //获取 TimerService,可以用于注册 timer
public abstract <X> void output(OutputTag<X> outputTag, X value);
public abstract K getCurrentKey();
}
/**
* Information available in an invocation of {@link #onTimer(long, OnTimerContext, Collector)}.
*/
public abstract class OnTimerContext extends Context {
public abstract TimeDomain timeDomain();
@Override
public abstract K getCurrentKey();
}
}
public class KeyedProcessOperator<K, IN, OUT>
extends AbstractUdfStreamOperator<OUT, KeyedProcessFunction<K, IN, OUT>>
implements OneInputStreamOperator<IN, OUT>, Triggerable<K, VoidNamespace> {
@Override
public void open() throws Exception {
super.open();
collector = new TimestampedCollector<>(output);
//注册了一个 TimerService,触发的目标是 KeyedProcessOperator 自身(实现了 Triggerable 接口)
InternalTimerService<VoidNamespace> internalTimerService =
getInternalTimerService("user-timers", VoidNamespaceSerializer.INSTANCE, this);
TimerService timerService = new SimpleTimerService(internalTimerService);
context = new ContextImpl(userFunction, timerService); //将 TimerService 封装在 ContextImpl 中
onTimerContext = new OnTimerContextImpl(userFunction, timerService);
}
//event timer 触发
@Override
public void onEventTime(InternalTimer<K, VoidNamespace> timer) throws Exception {
collector.setAbsoluteTimestamp(timer.getTimestamp());
invokeUserFunction(TimeDomain.EVENT_TIME, timer);
}
//processing timer 触发
@Override
public void onProcessingTime(InternalTimer<K, VoidNamespace> timer) throws Exception {
collector.eraseTimestamp();
invokeUserFunction(TimeDomain.PROCESSING_TIME, timer);
}
private void invokeUserFunction(
TimeDomain timeDomain,
InternalTimer<K, VoidNamespace> timer) throws Exception {
onTimerContext.timeDomain = timeDomain;
onTimerContext.timer = timer;
//user function 中的 timer 回调
userFunction.onTimer(timer.getTimestamp(), onTimerContext, collector);
onTimerContext.timeDomain = null;
onTimerContext.timer = null;
}
}
|
窗口
使用方法
窗口的使用有两种基本方式,分别是 Keyed Windows 和 Non-Keyed Windows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// Keyed Windows
stream
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/process() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
// Non-Keyed Windows
stream
.windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/process() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag" |
接下来,我们将重点关注 Keyed Windows 的实现方式,Non-Keyed Windows 实际上是基于 Keyed Windows 的一种特殊实现,在介绍了 Keyed Windows 的实现方式之后也会进行分析。
从基本的用法来看,首先使用 WindowAssigner 将 KeyedStream 转换为 WindowedStream;然后指定 1)窗口的计算逻辑,如聚合函数或 ProcessWindowFunction 2)触发窗口计算的 Trigger 3)能够修改窗口中元素的 Evictor,这时将会生成一个 WindowOperator (或其子类 EvictingWindowOperator)算子。窗口的主要的实现逻辑就在 WindowOperator 中。
Window 和 WindowAssigner
窗口在 Flink 内部就是使用抽象类 Window 来表示,每一个窗口都有一个绑定的最大 timestamp,一旦时间超过这个值表明窗口结束了。Window 有两个具体实现类,分别为 TimeWindow 和 GlobalWindow:TimeWindow 就是时间窗口,每一个时间窗口都有开始时间和结束时间,可以对时间窗口进行合并操作(主要是在 Session Window 中);GlobalWindow 是一个全局窗口,所有数据都属于该窗口,其最大 timestamp 是 Long.MAX_VALUE,使用单例模式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public abstract class Window {
public abstract long maxTimestamp();
}
public class TimeWindow extends Window {
private final long start;
private final long end;
@Override
public long maxTimestamp() {
return end - 1;
}
}
public class GlobalWindow extends Window {
private static final GlobalWindow INSTANCE = new GlobalWindow();
@Override
public long maxTimestamp() {
return Long.MAX_VALUE;
}
}
|
WindowAssigner 确定每一条消息属于哪些窗口,一条消息可能属于多个窗口(如在滑动窗口中,窗口之间可能有重叠);MergingWindowAssigner 是 WindowAssigner 的抽象子类,主要是提供了对时间窗口的合并功能。窗口合并的逻辑在 TimeWindow 提供的工具方法 mergeWindows(Collection<TimeWindow> windows, MergingWindowAssigner.MergeCallback<TimeWindow> c) 中,会对所有窗口按开始时间排序,存在重叠的窗口就可以进行合并。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
public abstract class WindowAssigner<T, W extends Window> implements Serializable {
public abstract Collection<W> assignWindows(T element, long timestamp, WindowAssignerContext context);
public abstract boolean isEventTime();
public abstract Trigger<T, W> getDefaultTrigger(StreamExecutionEnvironment env);
public abstract TypeSerializer<W> getWindowSerializer(ExecutionConfig executionConfig);
public abstract static class WindowAssignerContext {
public abstract long getCurrentProcessingTime();
}
}
public abstract class MergingWindowAssigner<T, W extends Window> extends WindowAssigner<T, W> {
private static final long serialVersionUID = 1L;
public abstract void mergeWindows(Collection<W> windows, MergeCallback<W> callback);
/**
* Callback to be used in {@link #mergeWindows(Collection, MergeCallback)} for specifying which
* windows should be merged.
*/
public interface MergeCallback<W> {
/**
* Specifies that the given windows should be merged into the result window.
*
* @param toBeMerged The list of windows that should be merged into one window.
* @param mergeResult The resulting merged window.
*/
void merge(Collection<W> toBeMerged, W mergeResult);
}
}
|
根据窗口类型和时间属性的不同,有不同的 WindowAssigner 的具体实现,如 TumblingEventTimeWindows, TumblingProcessingTimeWindows, SlidingEventTimeWindows, SlidingProcessingTimeWindows, EventTimeSessionWindows, ProcessingTimeSessionWindows, DynamicEventTimeSessionWindows, DynamicProcessingTimeSessionWindows, 以及 GlobalWindows。具体的实现逻辑这里就不赘述了。
Trigger
Trigger 用来确定一个窗口是否应该触发结果的计算,Trigger 提供了一系列的回调函数,根据回调函数返回的结果来决定是否应该触发窗口的计算。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
public abstract class Trigger<T, W extends Window> implements Serializable {
/**
* Called for every element that gets added to a pane. The result of this will determine
* whether the pane is evaluated to emit results.
*
* @param element The element that arrived.
* @param timestamp The timestamp of the element that arrived.
* @param window The window to which the element is being added.
* @param ctx A context object that can be used to register timer callbacks.
*/
public abstract TriggerResult onElement(T element, long timestamp, W window, TriggerContext ctx) throws Exception;
/**
* Called when a processing-time timer that was set using the trigger context fires.
*
* @param time The timestamp at which the timer fired.
* @param window The window for which the timer fired.
* @param ctx A context object that can be used to register timer callbacks.
*/
public abstract TriggerResult onProcessingTime(long time, W window, TriggerContext ctx) throws Exception;
/**
* Called when an event-time timer that was set using the trigger context fires.
*
* @param time The timestamp at which the timer fired.
* @param window The window for which the timer fired.
* @param ctx A context object that can be used to register timer callbacks.
*/
public abstract TriggerResult onEventTime(long time, W window, TriggerContext ctx) throws Exception;
/**
* Returns true if this trigger supports merging of trigger state and can therefore
* be used with a
* {@link org.apache.flink.streaming.api.windowing.assigners.MergingWindowAssigner}.
*
* <p>If this returns {@code true} you must properly implement
* {@link #onMerge(Window, OnMergeContext)}
*/
public boolean canMerge() {
return false;
}
/**
* Called when several windows have been merged into one window by the
* {@link org.apache.flink.streaming.api.windowing.assigners.WindowAssigner}.
*
* @param window The new window that results from the merge.
* @param ctx A context object that can be used to register timer callbacks and access state.
*/
public void onMerge(W window, OnMergeContext ctx) throws Exception {
throw new UnsupportedOperationException("This trigger does not support merging.");
}
}
|
Flink 提供了一些内置的 Trigger 实现,这些 Trigger 内部往往配合 timer 定时器进行使用,例如 EventTimeTrigger 是所有事件时间窗口的默认触发器,ProcessingTimeTrigger 是所有处理时间窗口的默认触发器,ContinuousEventTimeTrigger 和 ContinuousProcessingTimeTrigger 定期进行触发,CountTrigger 按照窗口内元素个数进行触发,DeltaTrigger 按照 DeltaFunction 进行触发,NeverTrigger 主要在全局窗口中使用,永远不会触发。
WindowOperator
Window 操作的主要处理逻辑在 WindowOperator 中。由于 window 的使用方式比较比较灵活,下面我们将先介绍最通用的窗口处理逻辑的实现,接着介绍窗口聚合函数的实现,最后介绍对可以合并的窗口的处理逻辑。
窗口处理逻辑
首先,我们来看一下 WindowOperator 的构造函数,确认它所依赖的比较重要的一些对象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
public class WindowOperator<K, IN, ACC, OUT, W extends Window>
extends AbstractUdfStreamOperator<OUT, InternalWindowFunction<ACC, OUT, K, W>>
implements OneInputStreamOperator<IN, OUT>, Triggerable<K, W> {
public WindowOperator(
WindowAssigner<? super IN, W> windowAssigner,
TypeSerializer<W> windowSerializer,
KeySelector<IN, K> keySelector,
TypeSerializer<K> keySerializer,
StateDescriptor<? extends AppendingState<IN, ACC>, ?> windowStateDescriptor,
InternalWindowFunction<ACC, OUT, K, W> windowFunction,
Trigger<? super IN, ? super W> trigger,
long allowedLateness,
OutputTag<IN> lateDataOutputTag) {
super(windowFunction);
this.windowAssigner = checkNotNull(windowAssigner);
this.windowSerializer = checkNotNull(windowSerializer);
this.keySelector = checkNotNull(keySelector);
this.keySerializer = checkNotNull(keySerializer);
this.windowStateDescriptor = windowStateDescriptor;
this.trigger = checkNotNull(trigger);
this.allowedLateness = allowedLateness;
this.lateDataOutputTag = lateDataOutputTag;
setChainingStrategy(ChainingStrategy.ALWAYS);
}
}
|
可以看出,构造 WindowOperator 时需要提供的比较重要的对象包括 WindowAssigner, Trigger, StateDescriptor<? extends AppendingState<IN, ACC>, ?> 以及 InternalWindowFunction<ACC, OUT, K, W>。其中,StateDescriptor<? extends AppendingState<IN, ACC>, ?> 是窗口状态的描述符,窗口的状态必须是 AppendingState 的子类;InternalWindowFunction<ACC, OUT, K, W> 是窗口的计算函数,从名字也可以看出,这是 Flink 内部使用的接口,不对外暴露。
在使用窗口时,最一般化的使用方式是通过 ProcessWindowFunction 或 WindowFunction 指定计算逻辑,ProcessWindowFunction 和 WindowFunction 会被包装成 InternalWindowFunction 的子类。WindowFunction 和 ProcessWindowFunction 的效果在某些场景下是一致的,但 ProcessWindowFunction 能够提供更多的窗口上下文信息,并且在之后的版本中可能会移除 WindowFunction 接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
public class WindowedStream<T, K, W extends Window> {
@Internal
public <R> SingleOutputStreamOperator<R> process(ProcessWindowFunction<T, R, K, W> function, TypeInformation<R> resultType) {
function = input.getExecutionEnvironment().clean(function);
return apply(new InternalIterableProcessWindowFunction<>(function), resultType, function);
}
private <R> SingleOutputStreamOperator<R> apply(InternalWindowFunction<Iterable<T>, R, K, W> function, TypeInformation<R> resultType, Function originalFunction) {
final String opName = generateOperatorName(windowAssigner, trigger, evictor, originalFunction, null);
KeySelector<T, K> keySel = input.getKeySelector();
WindowOperator<K, T, Iterable<T>, R, W> operator;
if (evictor != null) {
.......
} else {
ListStateDescriptor<T> stateDesc = new ListStateDescriptor<>("window-contents",
input.getType().createSerializer(getExecutionEnvironment().getConfig()));
operator =
new WindowOperator<>(windowAssigner,
windowAssigner.getWindowSerializer(getExecutionEnvironment().getConfig()),
keySel,
input.getKeyType().createSerializer(getExecutionEnvironment().getConfig()),
stateDesc,
function,
trigger,
allowedLateness,
lateDataOutputTag);
}
return input.transform(opName, resultType, operator);
}
}
|
可以看出,用户提供的 ProcessWindowFunction 被包装成 InternalIterableProcessWindowFunction 提供给 WindowOperator,并且 window 使用的状态是 ListState。
在 WindowOperator.open() 方法中会进行一些初始化操作,包括创建一个名为 window-timers 的 InternalTimerService 用于注册各种定时器,定时器的触发对象是 WindowOperator 自身。同时,会创建各种上下文对象,并初始化窗口状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
public class WindowOperator<K, IN, ACC, OUT, W extends Window>
extends AbstractUdfStreamOperator<OUT, InternalWindowFunction<ACC, OUT, K, W>>
implements OneInputStreamOperator<IN, OUT>, Triggerable<K, W> {
@Override
public void open() throws Exception {
super.open();
this.numLateRecordsDropped = metrics.counter(LATE_ELEMENTS_DROPPED_METRIC_NAME);
timestampedCollector = new TimestampedCollector<>(output);
internalTimerService =
getInternalTimerService("window-timers", windowSerializer, this);
triggerContext = new Context(null, null);
processContext = new WindowContext(null);
windowAssignerContext = new WindowAssigner.WindowAssignerContext() {
@Override
public long getCurrentProcessingTime() {
return internalTimerService.currentProcessingTime();
}
};
// create (or restore) the state that hold the actual window contents
// NOTE - the state may be null in the case of the overriding evicting window operator
if (windowStateDescriptor != null) {
windowState = (InternalAppendingState<K, W, IN, ACC, ACC>) getOrCreateKeyedState(windowSerializer, windowStateDescriptor);
}
.......
}
|
当消息到达时,在窗口算子中的处理流程大致如下:
- 通过
WindowAssigner 确定消息所在的窗口(可能属于多个窗口)
- 将消息加入到对应窗口的状态中
- 根据
Trigger.onElement 确定是否应该触发窗口结果的计算,如果使用 InternalWindowFunction 对窗口进行处理
- 注册一个定时器,在窗口结束时清理窗口状态
- 如果消息太晚到达,提交到 side output 中
如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
public class WindowOperator<K, IN, ACC, OUT, W extends Window>
extends AbstractUdfStreamOperator<OUT, InternalWindowFunction<ACC, OUT, K, W>>
implements OneInputStreamOperator<IN, OUT>, Triggerable<K, W> {
@Override
public void processElement(StreamRecord<IN> element) throws Exception {
final Collection<W> elementWindows = windowAssigner.assignWindows(
element.getValue(), element.getTimestamp(), windowAssignerContext);
//if element is handled by none of assigned elementWindows
boolean isSkippedElement = true;
final K key = this.<K>getKeyedStateBackend().getCurrentKey();
if (windowAssigner instanceof MergingWindowAssigner) {
......
} else {
for (W window: elementWindows) {
// drop if the window is already late
if (isWindowLate(window)) {
continue;
}
isSkippedElement = false;
windowState.setCurrentNamespace(window); //用 window 作为 state 的 namespace
windowState.add(element.getValue()); //消息加入到状态中
triggerContext.key = key;
triggerContext.window = window;
//通过 Trigger.onElement() 判断是否触发窗口结果的计算
TriggerResult triggerResult = triggerContext.onElement(element);
if (triggerResult.isFire()) {
ACC contents = windowState.get(); //获取窗口状态
if (contents == null) {
continue;
}
emitWindowContents(window, contents);
}
//是否需要清除窗口状态
if (triggerResult.isPurge()) {
windowState.clear();
}
//注册一个定时器,窗口结束后清理状态
registerCleanupTimer(window);
}
}
// 迟到的数据
if (isSkippedElement && isElementLate(element)) {
if (lateDataOutputTag != null){
sideOutput(element);
} else {
this.numLateRecordsDropped.inc();
}
}
}
protected void registerCleanupTimer(W window) {
long cleanupTime = cleanupTime(window);
if (cleanupTime == Long.MAX_VALUE) {
// don't set a GC timer for "end of time"
return;
}
if (windowAssigner.isEventTime()) {
triggerContext.registerEventTimeTimer(cleanupTime);
} else {
triggerContext.registerProcessingTimeTimer(cleanupTime);
}
}
//注意,这里窗口的清理时间是 window.maxTimestamp + allowedLateness
private long cleanupTime(W window) {
if (windowAssigner.isEventTime()) {
long cleanupTime = window.maxTimestamp() + allowedLateness;
return cleanupTime >= window.maxTimestamp() ? cleanupTime : Long.MAX_VALUE;
} else {
return window.maxTimestamp();
}
}
}
|
当定时器到期是,会调用 Trigger.onEventTime 判断是否需要触发窗口结果的计算;并且如果是窗口结束的定时器,会清理掉窗口的状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
public class WindowOperator<K, IN, ACC, OUT, W extends Window>
extends AbstractUdfStreamOperator<OUT, InternalWindowFunction<ACC, OUT, K, W>>
implements OneInputStreamOperator<IN, OUT>, Triggerable<K, W> {
@Override
public void onEventTime(InternalTimer<K, W> timer) throws Exception {
triggerContext.key = timer.getKey();
triggerContext.window = timer.getNamespace();
......
TriggerResult triggerResult = triggerContext.onEventTime(timer.getTimestamp());
if (triggerResult.isFire()) {//触发窗口结果的计算
ACC contents = windowState.get(); //获取状态
if (contents != null) {
emitWindowContents(triggerContext.window, contents);
}
}
if (triggerResult.isPurge()) {
windowState.clear();
}
if (windowAssigner.isEventTime() && isCleanupTime(triggerContext.window, timer.getTimestamp())) {
clearAllState(triggerContext.window, windowState, mergingWindows);
}
......
}
}
|
当需要进行窗口结果的计算时,会取出当前窗口所保存的状态,调用用户提供的 ProcessWindowFunction 进行处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public class WindowOperator<K, IN, ACC, OUT, W extends Window>
extends AbstractUdfStreamOperator<OUT, InternalWindowFunction<ACC, OUT, K, W>>
implements OneInputStreamOperator<IN, OUT>, Triggerable<K, W> {
private void emitWindowContents(W window, ACC contents) throws Exception {
timestampedCollector.setAbsoluteTimestamp(window.maxTimestamp());
processContext.window = window;
userFunction.process(triggerContext.key, window, processContext, contents, timestampedCollector);
}
}
public final class InternalIterableProcessWindowFunction<IN, OUT, KEY, W extends Window>
extends WrappingFunction<ProcessWindowFunction<IN, OUT, KEY, W>>
implements InternalWindowFunction<Iterable<IN>, OUT, KEY, W> {
@Override
public void process(KEY key, final W window, final InternalWindowContext context, Iterable<IN> input, Collector<OUT> out) throws Exception {
this.ctx.window = window;
this.ctx.internalContext = context;
ProcessWindowFunction<IN, OUT, KEY, W> wrappedFunction = this.wrappedFunction;
wrappedFunction.process(key, ctx, input, out);
}
}
|
增量窗口聚合
从上面对窗口处理逻辑的介绍我们可以看出,在使用 ProcessWindowFunction 来对窗口进行操作的一个重要缺陷是,需要把整个窗口内的所有消息全部缓存在 ListState 中,这无疑会导致性能问题。如果窗口的计算逻辑支持增量聚合操作,那么可以使用 ReduceFunction, AggregateFunction 或 FoldFunction 进行增量窗口聚合计算,这可以在很大程度上解决 ProcessWindowFunction 的性能问题。
使用 ReduceFunction, AggregateFunction 或 FoldFunction 进行在窗口聚合的底层实现是类似的,区别只在于聚合函数的不同。其中 AggregateFunction 是最通用的函数,我们以 AggregateFunction 为例进行分析。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
public class WindowedStream<T, K, W extends Window> {
public <ACC, R> SingleOutputStreamOperator<R> aggregate(
AggregateFunction<T, ACC, R> function,
TypeInformation<ACC> accumulatorType,
TypeInformation<R> resultType) {
checkNotNull(function, "function");
checkNotNull(accumulatorType, "accumulatorType");
checkNotNull(resultType, "resultType");
if (function instanceof RichFunction) {
throw new UnsupportedOperationException("This aggregation function cannot be a RichFunction.");
}
return aggregate(function, new PassThroughWindowFunction<K, W, R>(),
accumulatorType, resultType);
}
@PublicEvolving
public <ACC, V, R> SingleOutputStreamOperator<R> aggregate(
AggregateFunction<T, ACC, V> aggregateFunction,
WindowFunction<V, R, K, W> windowFunction,
TypeInformation<ACC> accumulatorType,
TypeInformation<R> resultType) {
......
final String opName = generateOperatorName(windowAssigner, trigger, evictor, aggregateFunction, windowFunction);
KeySelector<T, K> keySel = input.getKeySelector();
OneInputStreamOperator<T, R> operator;
if (evictor != null) {
.......
} else {
//注意,这里不再是 ListState,而是支持聚合操作的 AggregatingState,其聚合函数就是用户代码提供的
AggregatingStateDescriptor<T, ACC, V> stateDesc = new AggregatingStateDescriptor<>("window-contents",
aggregateFunction, accumulatorType.createSerializer(getExecutionEnvironment().getConfig()));
operator = new WindowOperator<>(windowAssigner,
windowAssigner.getWindowSerializer(getExecutionEnvironment().getConfig()),
keySel,
input.getKeyType().createSerializer(getExecutionEnvironment().getConfig()),
stateDesc,
new InternalSingleValueWindowFunction<>(windowFunction),
trigger,
allowedLateness,
lateDataOutputTag);
}
return input.transform(opName, resultType, operator);
}
}
|
可以看出来,如果使用了增量聚合函数,那么窗口的状态就不再是以 ListState 的形式保存窗口中的所有元素,而是 AggregatingState。这样,每当窗口中新消息到达时,在将消息添加到状态中的同时就会触发聚合函数的计算,这样在状态中就只需要保存聚合后的状态即可。
在上面直接使用 AggregateFunction 的情况下,用户代码中无法访问窗口的上下文信息。为了解决这个问题,可以将增量聚合函数和 ProcessWindowFunction 结合在一起使用,这样在提交窗口计算结果时也可以访问到窗口的上下文信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
public class WindowedStream<T, K, W extends Window> {
public <ACC, V, R> SingleOutputStreamOperator<R> aggregate(
AggregateFunction<T, ACC, V> aggregateFunction,
ProcessWindowFunction<V, R, K, W> windowFunction,
TypeInformation<ACC> accumulatorType,
TypeInformation<V> aggregateResultType,
TypeInformation<R> resultType) {
.......
final String opName = generateOperatorName(windowAssigner, trigger, evictor, aggregateFunction, windowFunction);
KeySelector<T, K> keySel = input.getKeySelector();
OneInputStreamOperator<T, R> operator;
if (evictor != null) {
........
} else {
AggregatingStateDescriptor<T, ACC, V> stateDesc = new AggregatingStateDescriptor<>("window-contents",
aggregateFunction, accumulatorType.createSerializer(getExecutionEnvironment().getConfig()));
operator = new WindowOperator<>(windowAssigner,
windowAssigner.getWindowSerializer(getExecutionEnvironment().getConfig()),
keySel,
input.getKeyType().createSerializer(getExecutionEnvironment().getConfig()),
stateDesc,
new InternalSingleValueProcessWindowFunction<>(windowFunction),
trigger,
allowedLateness,
lateDataOutputTag);
}
return input.transform(opName, resultType, operator);
}
}
|
合并窗口
前面在介绍窗口的实现逻辑时都只是考虑了窗口不会发生合并的情况。在一些情况下,窗口的边界不是固定的,可能会随着消息的到达不断进行调整,例如 session window,这就情况下就会发生窗口的合并。
可以合并的窗口相比于不可以合并的窗口,在 WindowOperator.open 方法中除了初始化窗口状态之外,还会初始化一个新的 mergingSetsState 用于保存窗口合并状态:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
public class WindowOperator<K, IN, ACC, OUT, W extends Window>
extends AbstractUdfStreamOperator<OUT, InternalWindowFunction<ACC, OUT, K, W>>
implements OneInputStreamOperator<IN, OUT>, Triggerable<K, W> {
@Override
public void open() throws Exception {
......
// create (or restore) the state that hold the actual window contents
// NOTE - the state may be null in the case of the overriding evicting window operator
if (windowStateDescriptor != null) {
windowState = (InternalAppendingState<K, W, IN, ACC, ACC>) getOrCreateKeyedState(windowSerializer, windowStateDescriptor);
}
// create the typed and helper states for merging windows
if (windowAssigner instanceof MergingWindowAssigner) {
// store a typed reference for the state of merging windows - sanity check
// 窗口状态必须是可以合并的
if (windowState instanceof InternalMergingState) {
windowMergingState = (InternalMergingState<K, W, IN, ACC, ACC>) windowState;
} else if (windowState != null) {
throw new IllegalStateException(
"The window uses a merging assigner, but the window state is not mergeable.");
}
@SuppressWarnings("unchecked")
final Class<Tuple2<W, W>> typedTuple = (Class<Tuple2<W, W>>) (Class<?>) Tuple2.class;
final TupleSerializer<Tuple2<W, W>> tupleSerializer = new TupleSerializer<>(
typedTuple,
new TypeSerializer[] {windowSerializer, windowSerializer});
final ListStateDescriptor<Tuple2<W, W>> mergingSetsStateDescriptor =
new ListStateDescriptor<>("merging-window-set", tupleSerializer);
// 创建一个 ListState<Tuple2<W,W>> 用于保存合并的窗口集合
// get the state that stores the merging sets
mergingSetsState = (InternalListState<K, VoidNamespace, Tuple2<W, W>>)
getOrCreateKeyedState(VoidNamespaceSerializer.INSTANCE, mergingSetsStateDescriptor);
mergingSetsState.setCurrentNamespace(VoidNamespace.INSTANCE);
}
}
}
|
相比于不可合并的窗口,可以合并的窗口实现上的一个难点就在于窗口合并时状态的处理,这需要依赖于 mergingSetsState 和 MergingWindowSet。我们先来梳理下窗口合并时窗口状态的处理,然后再详细地看具体的实现。
首先,可以合并的窗口要求窗口状态必须是可以合并的,只有这样,当两个窗口进行合并时其状态才可以正确地保存,ListState,ReducingState和 AggregatingState 都继承了 MergingState 接口。 InternalMergingState 接口提供了将多个 namespace 关联的状态合并到目标 namespace 的功能,注意方法的签名是将一组作为 source 的 namespace 合并到作为 target 的 namespace :
1
2
3
4
5
6
7
8
9
10
11
12
|
public interface InternalMergingState<K, N, IN, SV, OUT> extends InternalAppendingState<K, N, IN, SV, OUT>, MergingState<IN, OUT> {
/**
* Merges the state of the current key for the given source namespaces into the state of
* the target namespace.
*
* @param target The target namespace where the merged state should be stored.
* @param sources The source namespaces whose state should be merged.
*
* @throws Exception The method may forward exception thrown internally (by I/O or functions).
*/
void mergeNamespaces(N target, Collection<N> sources) throws Exception;
}
|
现在我们考虑窗口合并的情况。如下图所示,w1 窗口的状态 s1 (w1 也是 s1 的 namespace),w2 窗口的状态 s2 (w2 也是 s2 的 namespace),现在新增了一个窗口 w3,则应该对窗口进行合并,将 w1, w2, w3 合并为一个新的窗口 w4。在这种情况下,我们也需要对窗口的状态进行合并。按照常规的思路,我们应该以 w4 作为合并之后窗口状态的 namespace,调用 mergeNamespaces(w4, Collection(w1,w2,w3)) 进行状态合并。但是以 w4 作为 namespace 的状态并不存在,因此考虑继续使用 w1 作为窗口 w4 状态的 namespace,即调用 mergeNamespaces(w1, Collection(w2,w3)) 进行状态合并,但要将 w4 -> w1 的映射关系保存起来,以便查找窗口的状态。这种 窗口 -> 窗口状态的 namespace 的映射关系就保存在 InternalListState<K, VoidNamespace, Tuple2<W, W>> mergingSetsState 中。

WindowOperator 内部对窗口合并的处理如下,主要是借助 MergingWindowSet 进行窗口的合并:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
public class WindowOperator<K, IN, ACC, OUT, W extends Window>
extends AbstractUdfStreamOperator<OUT, InternalWindowFunction<ACC, OUT, K, W>>
implements OneInputStreamOperator<IN, OUT>, Triggerable<K, W> {
@Override
public void processElement(StreamRecord<IN> element) throws Exception {
final Collection<W> elementWindows = windowAssigner.assignWindows(
element.getValue(), element.getTimestamp(), windowAssignerContext);
boolean isSkippedElement = true;
final K key = this.<K>getKeyedStateBackend().getCurrentKey();
if (windowAssigner instanceof MergingWindowAssigner) {
MergingWindowSet<W> mergingWindows = getMergingWindowSet(); //获取 MergingWindowSet,这是辅助进行窗口合并的工具
for (W window : elementWindows) {
// adding the new window might result in a merge, in that case the actualWindow
// is the merged window and we work with that. If we don't merge then
// actualWindow == window
W actualWindow = mergingWindows.addWindow(window,
new MergingWindowSet.MergeFunction<W>() { //这是合并窗口的回调函数
@Override
public void merge(
W mergeResult, //这是合并后的窗口
Collection<W> mergedWindows, //这是被合并的窗口
W stateWindowResult, //这是用作合并后窗口状态的 namespace
Collection<W> mergedStateWindows //这是被合并的状态的 namespace
) throws Exception {
.......
triggerContext.key = key;
triggerContext.window = mergeResult;
triggerContext.onMerge(mergedWindows); //调用 Trigger.onMerger 判断是否需要进行触发
for (W m : mergedWindows) {
triggerContext.window = m;
triggerContext.clear();
deleteCleanupTimer(m);
}
// 合并窗口状态
// merge the merged state windows into the newly resulting state window
evictingWindowState.mergeNamespaces(stateWindowResult, mergedStateWindows);
}
});
// drop if the window is already late
if (isWindowLate(actualWindow)) {
mergingWindows.retireWindow(actualWindow);
continue;
}
isSkippedElement = false;
W stateWindow = mergingWindows.getStateWindow(actualWindow);
if (stateWindow == null) {
throw new IllegalStateException("Window " + window + " is not in in-flight window set.");
}
evictingWindowState.setCurrentNamespace(stateWindow);
evictingWindowState.add(element);
triggerContext.key = key;
triggerContext.window = actualWindow;
evictorContext.key = key;
evictorContext.window = actualWindow;
TriggerResult triggerResult = triggerContext.onElement(element);
if (triggerResult.isFire()) {
Iterable<StreamRecord<IN>> contents = evictingWindowState.get();
if (contents == null) {
// if we have no state, there is nothing to do
continue;
}
emitWindowContents(actualWindow, contents, evictingWindowState);
}
if (triggerResult.isPurge()) {
evictingWindowState.clear();
}
registerCleanupTimer(actualWindow);
}
// need to make sure to update the merging state in state
mergingWindows.persist();
} else {
........
}
}
}
|
窗口合并的主要逻辑被封装在 MergingWindowSet 中,需要重点关注合并时对窗口 -> 窗口状态的 namespace 的映射关系的处理,结合前面的分析应该可以理解:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
public class MergingWindowSet<W extends Window> {
private final Map<W, W> mapping; //这里保存的就是 `窗口 -> 窗口状态的 namespace` 的映射关系
public W addWindow(W newWindow, MergeFunction<W> mergeFunction) throws Exception {
List<W> windows = new ArrayList<>();
windows.addAll(this.mapping.keySet());
windows.add(newWindow);
//确定能够合并的窗口,在回调函数中将窗口的合并结果保存在mergeResults
final Map<W, Collection<W>> mergeResults = new HashMap<>();
windowAssigner.mergeWindows(windows,
new MergingWindowAssigner.MergeCallback<W>() {
@Override
public void merge(Collection<W> toBeMerged, W mergeResult) {
mergeResults.put(mergeResult, toBeMerged);
}
});
W resultWindow = newWindow;
boolean mergedNewWindow = false;
// perform the merge
for (Map.Entry<W, Collection<W>> c: mergeResults.entrySet()) {
W mergeResult = c.getKey(); //合并后产生的窗口
Collection<W> mergedWindows = c.getValue(); //被合并的窗口
// if our new window is in the merged windows make the merge result the
// result window
if (mergedWindows.remove(newWindow)) {
mergedNewWindow = true;
resultWindow = mergeResult;
}
// pick any of the merged windows and choose that window's state window
// as the state window for the merge result
//从需要被合并的窗口中选择一个作为合并后状态的namespace
W mergedStateWindow = this.mapping.get(mergedWindows.iterator().next());
// figure out the state windows that we are merging
List<W> mergedStateWindows = new ArrayList<>();
for (W mergedWindow: mergedWindows) {
//移除旧的映射关系
W res = this.mapping.remove(mergedWindow);
if (res != null) {
mergedStateWindows.add(res);
}
}
//新的映射关系
this.mapping.put(mergeResult, mergedStateWindow);
// don't put the target state window into the merged windows
mergedStateWindows.remove(mergedStateWindow);
// don't merge the new window itself, it never had any state associated with it
// i.e. if we are only merging one pre-existing window into itself
// without extending the pre-existing window
if (!(mergedWindows.contains(mergeResult) && mergedWindows.size() == 1)) {
//调用回调函数进行状态的合并
mergeFunction.merge(
mergeResult, //合并后的窗口
mergedWindows, //需要被合并的窗口
this.mapping.get(mergeResult), //用作状态 namespace 的 window
mergedStateWindows); //需要合并到最终结果的 namespace
}
}
// the new window created a new, self-contained window without merging
if (mergeResults.isEmpty() || (resultWindow.equals(newWindow) && !mergedNewWindow)) {
this.mapping.put(resultWindow, resultWindow);
}
return resultWindow;
}
}
|
Evictor
Flink 的窗口操作还提供了一个可选的 evitor,允许在调用 InternalWindowFunction 计算窗口结果之前或之后移除窗口中的元素。在这种情况下,就不能对窗口进行增量聚合操作了,窗口内的所有元素必须保存在 ListState 中,因而对性能会有一定影响。
Evictor 提拱了两个方法,分别在 InternalWindowFunction 处理之前和处理之后调用:
1
2
3
4
|
public interface Evictor<T, W extends Window> extends Serializable {
void evictBefore(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
void evictAfter(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
}
|
以 CountEvictor 为例,只会保留一定数量的元素在窗口中,超出的部分被移除掉:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
public class CountEvictor<W extends Window> implements Evictor<Object, W> {
@Override
public void evictBefore(Iterable<TimestampedValue<Object>> elements, int size, W window, EvictorContext ctx) {
if (!doEvictAfter) {
evict(elements, size, ctx);
}
}
@Override
public void evictAfter(Iterable<TimestampedValue<Object>> elements, int size, W window, EvictorContext ctx) {
if (doEvictAfter) {
evict(elements, size, ctx);
}
}
private void evict(Iterable<TimestampedValue<Object>> elements, int size, EvictorContext ctx) {
if (size <= maxCount) {
return;
} else {
int evictedCount = 0;
for (Iterator<TimestampedValue<Object>> iterator = elements.iterator(); iterator.hasNext();){
iterator.next();
evictedCount++;
if (evictedCount > size - maxCount) {
break;
} else {
//超出的部分都移除
iterator.remove();
}
}
}
}
}
|
在使用了 Evictor 的情况下,会生成 EvictingWindowOperator 算子,EvictingWindowOperator 是 WindowOperator 的子类,会在触发窗口计算时调用 Evictor:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
class WindowedStream {
public <ACC, V, R> SingleOutputStreamOperator<R> aggregate(
AggregateFunction<T, ACC, V> aggregateFunction,
ProcessWindowFunction<V, R, K, W> windowFunction,
TypeInformation<ACC> accumulatorType,
TypeInformation<V> aggregateResultType,
TypeInformation<R> resultType) {
if (evictor != null) {
TypeSerializer<StreamRecord<T>> streamRecordSerializer =
(TypeSerializer<StreamRecord<T>>) new StreamElementSerializer(input.getType().createSerializer(getExecutionEnvironment().getConfig()));
//即便是使用了增量聚合函数,状态仍然是以 `ListState` 形式保存的
ListStateDescriptor<StreamRecord<T>> stateDesc =
new ListStateDescriptor<>("window-contents", streamRecordSerializer);
//生成了 EvictingWindowOperator
operator = new EvictingWindowOperator<>(windowAssigner,
windowAssigner.getWindowSerializer(getExecutionEnvironment().getConfig()),
keySel,
input.getKeyType().createSerializer(getExecutionEnvironment().getConfig()),
stateDesc,
new InternalAggregateProcessWindowFunction<>(aggregateFunction, windowFunction),
trigger,
evictor,
allowedLateness,
lateDataOutputTag);
} else {
.......
}
}
}
public class WindowOperator<K, IN, ACC, OUT, W extends Window>
extends AbstractUdfStreamOperator<OUT, InternalWindowFunction<ACC, OUT, K, W>>
implements OneInputStreamOperator<IN, OUT>, Triggerable<K, W> {
private void emitWindowContents(W window, Iterable<StreamRecord<IN>> contents, ListState<StreamRecord<IN>> windowState) throws Exception {
timestampedCollector.setAbsoluteTimestamp(window.maxTimestamp());
// Work around type system restrictions...
FluentIterable<TimestampedValue<IN>> recordsWithTimestamp = FluentIterable
.from(contents)
.transform(new Function<StreamRecord<IN>, TimestampedValue<IN>>() {
@Override
public TimestampedValue<IN> apply(StreamRecord<IN> input) {
return TimestampedValue.from(input);
}
});
//调用 InternalWindowFunction 之前
evictorContext.evictBefore(recordsWithTimestamp, Iterables.size(recordsWithTimestamp));
FluentIterable<IN> projectedContents = recordsWithTimestamp
.transform(new Function<TimestampedValue<IN>, IN>() {
@Override
public IN apply(TimestampedValue<IN> input) {
return input.getValue();
}
});
processContext.window = triggerContext.window;
//调用 InternalWindowFunction 计算结果
userFunction.process(triggerContext.key, triggerContext.window, processContext, projectedContents, timestampedCollector);
//调用 InternalWindowFunction 之前
evictorContext.evictAfter(recordsWithTimestamp, Iterables.size(recordsWithTimestamp));
//work around to fix FLINK-4369, remove the evicted elements from the windowState.
//this is inefficient, but there is no other way to remove elements from ListState, which is an AppendingState.
windowState.clear();
for (TimestampedValue<IN> record : recordsWithTimestamp) {
windowState.add(record.getStreamRecord());
}
}
}
|
AllWindowedStream
前面我们介绍的实际上是 Keyed Windows 的具体实现,它是在 KeyedStream 上进行的窗口操作,所以消息会按照 key 进行分流,这也是窗口最常用的到的的应用场景。但是,针对普通的 Non-Keyed Stream,同样可以进行窗口操作。在这种情况下,DataStream.windowAll(...) 操作得到 AllWindowedStream。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public class AllWindowedStream<T, W extends Window> {
public AllWindowedStream(DataStream<T> input,
WindowAssigner<? super T, W> windowAssigner) {
this.input = input.keyBy(new NullByteKeySelector<T>());
this.windowAssigner = windowAssigner;
this.trigger = windowAssigner.getDefaultTrigger(input.getExecutionEnvironment());
}
}
public class NullByteKeySelector<T> implements KeySelector<T, Byte> {
@Override
public Byte getKey(T value) throws Exception {
return 0;
}
}
|
所以很明显,Non-Keyed Windows 实际上就是基于 Keyed Windows 的一种特殊实现,只是使用了一种特殊的 NullByteKeySelector,这样所有的消息得到的 Key 都是一样的。Non-Keyed Windows 的一个问题在于,由于所有消息的 key 都是一样的,那么所有的消息最终都会被同一个 Task 处理,这个 Task 也会成为整个作业的瓶颈。
小结
时间属性和窗口操作是对流处理系统能力的极大增强。在这篇文章中,我们由 Dataflow Model 引申出时间域(time domain),水位线(watermark),窗口模型(windowing model),触发器(triggering model)等概念,并一一介绍了这些机制在 Flink 内部的实现方式。
参考
-EOF-