在这篇文章中,我们将探讨一个 Flink 作业在实际运行时,不同的 Task 之间是如何进行数据交换的。由于不同的 Task 可能并非运行在同一个 TaskManager 中,因而数据传输的过程中必然涉及到网络通信,文中也会对 Flink 的网络栈的实现,包括反压机制等,进行分析。
概览
Flink 的数据交换机制在设计时遵循两个基本原则:
1. 数据交换的控制流(例如,为初始化数据交换而发出的消息)是由接收端发起的
2. 数据交换的数据流(例如,在网络中实际传输的数据被抽象为 IntermediateResult 的概念)是可插拔的。这意味着系统基于相同的实现逻辑既可以支持 Streaming 模式也可以支持 Batch 模式下数据的传输
我们知道,在一个 TaskManager 中可能会同时并行运行多个 Task,每个 Task 都在单独的线程中运行。在不同的 TaskManager 中运行的 Task 之间进行数据传输要基于网络进行通信。实际上,是 TaskManager 和另一个 TaskManager 之间通过网络进行通信,通信是基于 Netty 创建的标准的 TCP 连接,同一个 TaskManager 内运行的不同 Task 会复用网络连接。
关于 Flink 的数据交换机制的具体流程,Flink 的 wiki 中给出了一个比较详细的说明,在这里引述一下其中的内容,对我们后续分析具体的实现细节很有帮助。
数据交换的控制流
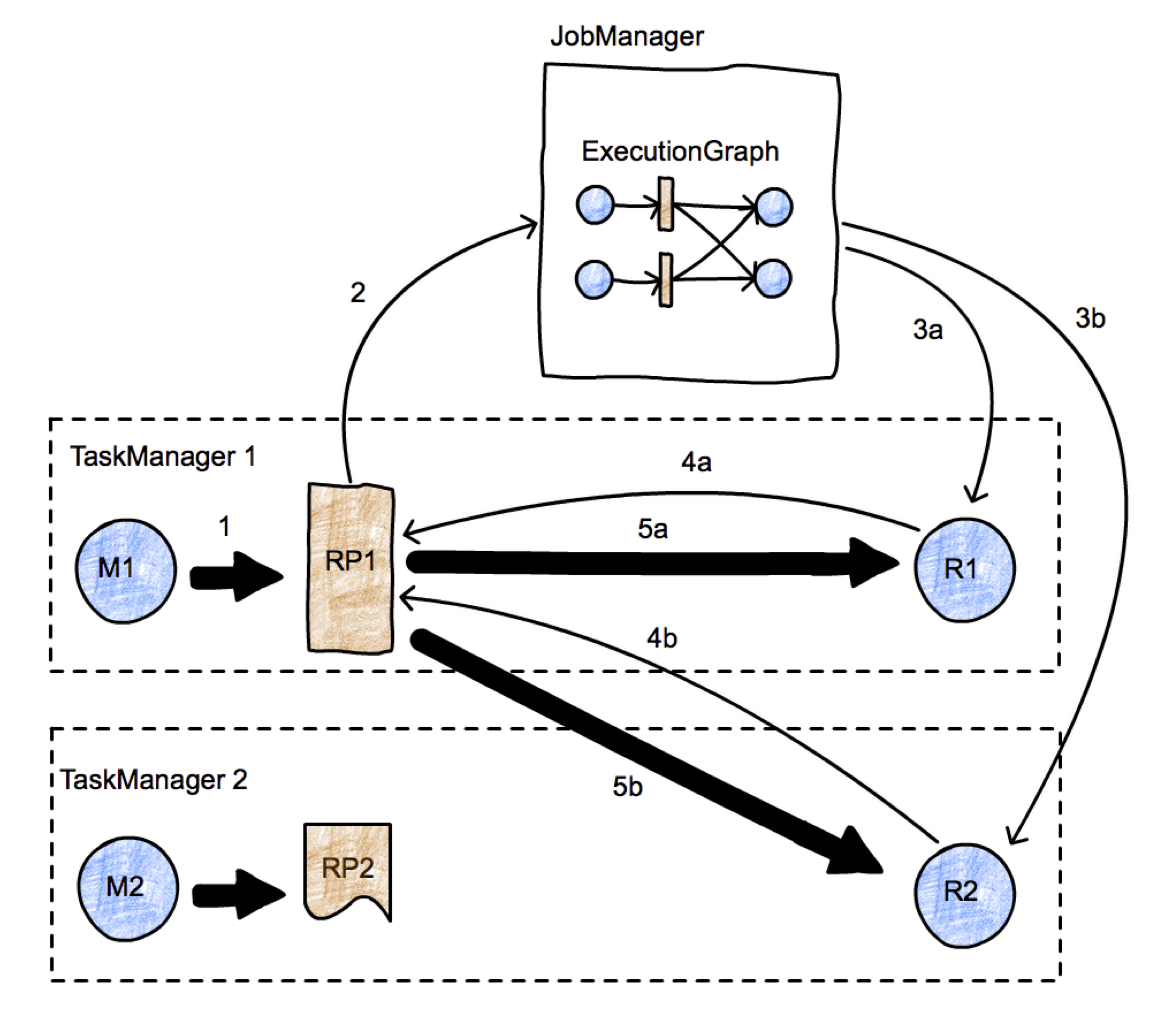 上图代表了一个简单的 map-reduce 类型的作业,有两个并行的任务。有两个 TaskManager,每个 TaskManager 都分别运行一个 map Task 和一个 reduce Task。我们重点观察 M1 和 R2 这两个 Task 之间的数据传输的发起过程。数据传输用粗箭头表示,消息用细箭头表示。首先,M1 产出了一个 ResultPartition(RP1)(箭头1)。当这个 RP 可以被消费是,会告知 JobManager(箭头2)。JobManager 会通知想要接收这个 RP 分区数据的接收者(tasks R1 and R2)当前分区数据已经准备好。如果接受放还没有被调度,这将会触发对应任务的部署(箭头 3a,3b)。接着,接受方会从 RP 中请求数据(箭头 4a,4b)。这将会初始化 Task 之间的数据传输(5a,5b),数据传输可能是本地的(5a),也可能是通过 TaskManager 的网络栈进行(5b)。对于一个 RP 什么时候告知 JobManager 当前已经出于可用状态,在这个过程中是有充分的自由度的:例如,如果在 RP1 在告知 JM 之前已经完整地产出了所有的数据(甚至可能写入了本地文件),那么相应的数据传输更类似于 Batch 的批交换;如果 RP1 在第一条记录产出时就告知 JM,那么就是 Streaming 流交换。
上图代表了一个简单的 map-reduce 类型的作业,有两个并行的任务。有两个 TaskManager,每个 TaskManager 都分别运行一个 map Task 和一个 reduce Task。我们重点观察 M1 和 R2 这两个 Task 之间的数据传输的发起过程。数据传输用粗箭头表示,消息用细箭头表示。首先,M1 产出了一个 ResultPartition(RP1)(箭头1)。当这个 RP 可以被消费是,会告知 JobManager(箭头2)。JobManager 会通知想要接收这个 RP 分区数据的接收者(tasks R1 and R2)当前分区数据已经准备好。如果接受放还没有被调度,这将会触发对应任务的部署(箭头 3a,3b)。接着,接受方会从 RP 中请求数据(箭头 4a,4b)。这将会初始化 Task 之间的数据传输(5a,5b),数据传输可能是本地的(5a),也可能是通过 TaskManager 的网络栈进行(5b)。对于一个 RP 什么时候告知 JobManager 当前已经出于可用状态,在这个过程中是有充分的自由度的:例如,如果在 RP1 在告知 JM 之前已经完整地产出了所有的数据(甚至可能写入了本地文件),那么相应的数据传输更类似于 Batch 的批交换;如果 RP1 在第一条记录产出时就告知 JM,那么就是 Streaming 流交换。
字节缓冲区在两个 Task 之间的传输
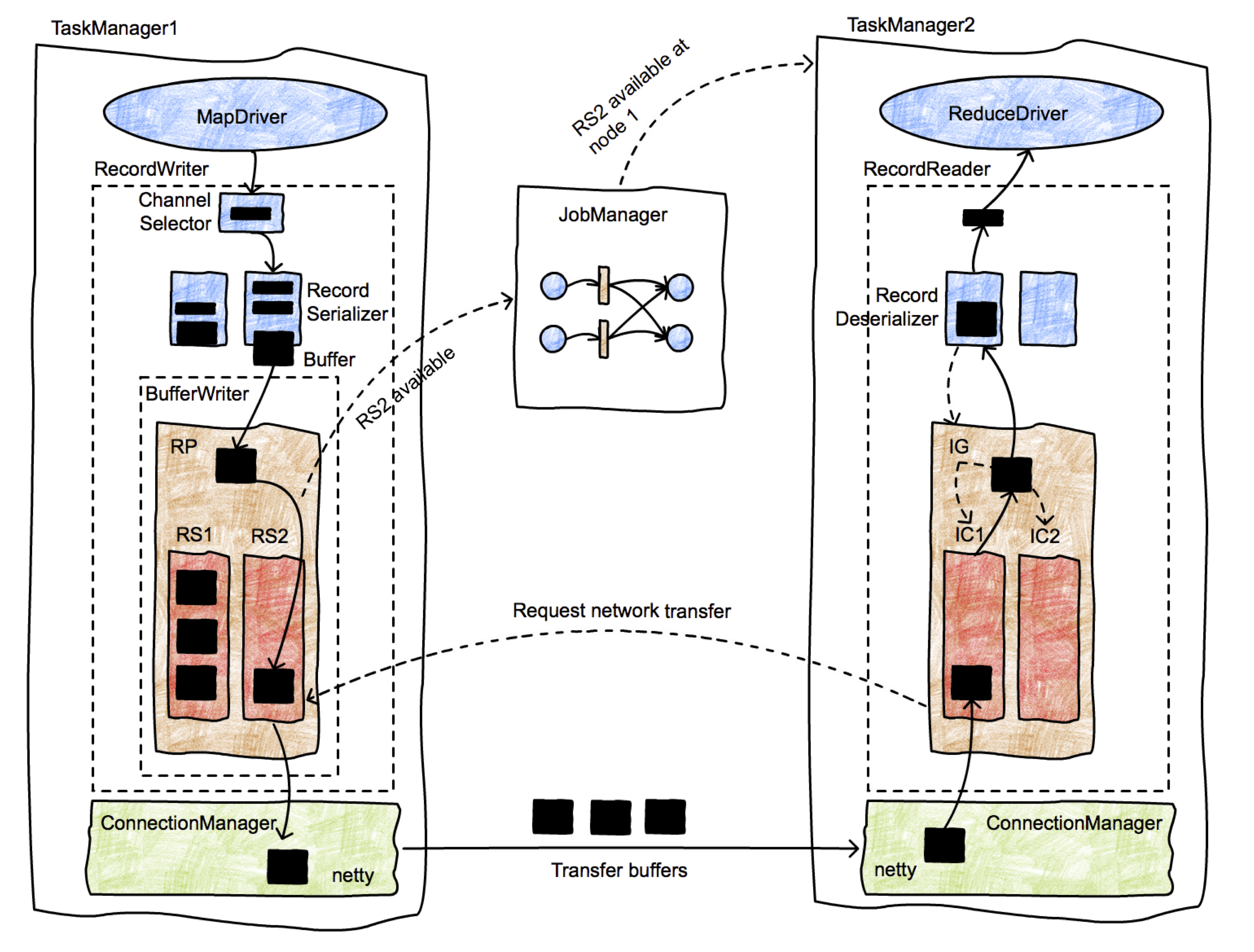
上面这张图展示了一个细节更加丰富的流程,描述了一条数据记录从生产者传输到消费者的完整生命周期。
最初,MapDriver 生成数据记录(通过 Collector 收集)并传递给 RecordWriter 对象。RecordWriter 包含一组序列化器,每个消费数据的 Task 分别对应一个。 ChannelSelector 会选择一个或多个序列化器处理记录。例如,如果记录需要被广播,那么就会被交给每一个序列化器进行处理;如果记录是按照 hash 进行分区的,ChannelSelector 会计算记录的哈希值,然后选择对应的序列化器。
序列化器会将记录序列化为二进制数据,并将其存放在固定大小的 buffer 中(一条记录可能需要跨越多个 buffer)。这些 buffer 被交给 BufferWriter 处理,写入到 ResulePartition(RP)中。 RP 有多个子分区(ResultSubpartitions - RSs)构成,每一个子分区都只收集特定消费者需要的数据。在上图中,需要被第二个 reducer (在 TaskManager 2 中)消费的记录被放在 RS2 中。由于第一个 Buffer 已经生成,RS2 就变成可被消费的状态了(注意,这个行为实现了一个 streaming shuffle),接着它通知 JobManager。
JobManager查找RS2的消费者,然后通知 TaskManager 2 一个数据块已经可以访问了。通知TM2的消息会被发送到InputChannel,该inputchannel被认为是接收这个buffer的,接着通知RS2可以初始化一个网络传输了。然后,RS2通过TM1的网络栈请求该buffer,然后双方基于 Netty 准备进行数据传输。网络连接是在TaskManager(而非特定的task)之间长时间存在的。
JobManager 查找 RS2 的消费者,并通知 TM2 一个数据块已经可以被访问了。通知 TM2 的消息被传递给 InputChannel,这个 InputChannel 负责接受这个 buffer。紧接着就通知 RS2 可以发起一起网络传输。 RS2 将 buffer 交给 TM1 的网络栈,然后基于 Netty 进行数据传输。网络连接是在 TM 之间长期存在在,而不是在独立的 Task 之间。
一旦 Buffer 被 TM2 接收,它同样会经过一个类似的结构,起始于 InputChannel,进入 InputGate(它包含多个IC),最终进入一个反序列化器(RecordDeserializer),它会从 buffer 中将记录还原成指定类型的对象,然后将其传递给接收数据的 Task。
几个基本概念
在开始介绍 Flink 中数据交换机制的具体实现之前,我们有必要先对几个重要的概念进行一下梳理。这几个概念主要是到对 Flink 作业运行时产生的中间结果的抽象。
IntermediateDataset 是在 JobGraph 中对中间结果的抽象。我们知道,JobGraph 是对 StreamGraph 进一步进行优化后得到的逻辑图,它尽量把可以 chain 到一起 operator 合并为一个 JobVertex,而 IntermediateDataset 就表示一个 JobVertex 的输出结果。JobVertex 的输入是 JobEdge,而 JobEdge 可以看作是 IntermediateDataset 的消费者。一个 JobVertex 也可能产生多个 IntermediateDataset。需要说明的一点是,目前一个 IntermediateDataset 实际上只会有一个 JobEdge 作为消费者,也就是说,一个 JobVertex 的下游有多少 JobVertex 需要依赖当前节点的数据,那么当前节点就有对应数量的 IntermediateDataset。
在 JobManager 中,JobGraph 被进一步转换成可以被调度的并行化版本的执行图,即 ExecutionGraph。在 ExecutionGraph 中,和 JobVertex 对应的节点是 ExecutionJobVertex,和 IntermediateDataset 对应的则是 IntermediataResult。由于一个节点在实际运行时可能有多个并行子任务同时运行,所以 ExecutionJobVertex 按照并行度的设置被拆分为多个 ExecutionVertex,每一个表示一个并行的子任务。同样的,一个 IntermediataResult 也会被拆分为多个 IntermediateResultPartition,IntermediateResultPartition 对应 ExecutionVertex 的输出结果。一个 IntermediateDataset 只有一个消费者,那么一个 IntermediataResult 也只会有一个消费者;但是到了 IntermediateResultPartition 这里,由于节点被拆分成了并行化的节点,所以一个 IntermediateResultPartition 可能会有多个 ExecutionEdge 作为消费者。
ResultPartition 和 ResultSubpartition
ExecutionGraph 还是 JobManager 中用于描述作业拓扑的一种逻辑上的数据结构,其中表示并行子任务的 ExecutionVertex 会被调度到 TaskManager 中执行,一个 Task 对应一个 ExecutionVertex。同 ExecutionVertex 的输出结果 IntermediateResultPartition 相对应的则是 ResultPartition。IntermediateResultPartition 可能会有多个 ExecutionEdge 作为消费者,那么在 Task 这里,ResultPartition 就会被拆分为多个 ResultSubpartition,下游每一个需要从当前 ResultPartition 消费数据的 Task 都会有一个专属的 ResultSubpartition。
ResultPartitionType 指定了 ResultPartition 的不同属性,这些属性包括是否流水线模式、是否会产生反压以及是否限制使用的 Network buffer 的数量。ResultPartitionType 有三个枚举值:
BLOCKING:非流水线模式,无反压,不限制使用的网络缓冲的数量PIPELINED:流水线模式,有反压,不限制使用的网络缓冲的数量PIPELINED_BOUNDED:流水线模式,有反压,限制使用的网络缓冲的数量
其中是否流水线模式这个属性会对消费行为产生很大的影响:如果是流水线模式,那么在 ResultPartition 接收到第一个 Buffer 时,消费者任务就可以进行准备消费;而如果非流水线模式,那么消费者将等到生产端任务生产完数据之后才进行消费。目前在 Stream 模式下使用的类型是 PIPELINED_BOUNDED。
在 Task 中,InputGate 是对输入的封装,InputGate 是和 JobGraph 中 JobEdge 一一对应的。也就是说,InputGate 实际上对应的是该 Task 依赖的上游算子(包含多个并行子任务),每个 InputGate 消费了一个或多个 ResultPartition。InputGate 由 InputChannel 构成,InputChannel 和 ExecutionGraph 中的 ExecutionEdge 一一对应;也就是说, InputChannel 和 ResultSubpartition 一一相连,一个 InputChannel 接收一个 ResultSubpartition 的输出。根据读取的 ResultSubpartition 的位置,InputChannel 有 LocalInputChannel 和 RemoteInputChannel 两种不同的实现。
数据交换机制的具体实现
数据交换从本质上来说就是一个典型的生产者-消费者模型,上游算子生产数据到 ResultPartition 中,下游算子通过 InputGate 消费数据。由于不同的 Task 可能在同一个 TaskManager 中运行,也可能在不同的 TaskManager 中运行:对于前者,不同的 Task 其实就是同一个 TaskManager 进程中的不同的线程,它们的数据交换就是在本地不同线程间进行的;对于后者,必须要通过网络进行通信。我们分别来介绍下这两个不同场景下数据交换的具体实现。通过合理的设计和抽象,Flink 确保本地数据交换和通过网络进行数据交换可以复用同一套代码。
Task 的输入和输出
Task 的输出
Task 产出的每一个 ResultPartition 都有一个关联的 ResultPartitionWriter,同时也都有一个独立的 LocalBufferPool 负责提供写入数据所需的 buffer。ResultPartion 实现了 ResultPartitionWriter 接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
public class ResultPartition implements ResultPartitionWriter, BufferPoolOwner {
/** Type of this partition. Defines the concrete subpartition implementation to use. */
private final ResultPartitionType partitionType;
// ResultPartition 由 ResultSubpartition 构成,
// ResultSubpartition 的数量由下游消费 Task 数和 DistributionPattern 来决定。
// 例如,如果是 FORWARD,则下游只有一个消费者;如果是 SHUFFLE,则下游消费者的数量和下游算子的并行度一样
/** The subpartitions of this partition. At least one. */
private final ResultSubpartition[] subpartitions;
//ResultPartitionManager 管理当前 TaskManager 所有的 ResultPartition
private final ResultPartitionManager partitionManager;
//通知当前ResultPartition有数据可供消费的回调函数回调
private final ResultPartitionConsumableNotifier partitionConsumableNotifier;
private BufferPool bufferPool;
//在有数据产出时,是否需要发送消息来调度或更新消费者(Stream模式下调度模式为 ScheduleMode.EAGER,无需发通知)
private final boolean sendScheduleOrUpdateConsumersMessage;
//是否已经通知了消费者
private boolean hasNotifiedPipelinedConsumers;
public ResultPartition(
String owningTaskName,
TaskActions taskActions, // actions on the owning task
JobID jobId,
ResultPartitionID partitionId,
ResultPartitionType partitionType,
int numberOfSubpartitions,
int numTargetKeyGroups,
ResultPartitionManager partitionManager,
ResultPartitionConsumableNotifier partitionConsumableNotifier,
IOManager ioManager,
boolean sendScheduleOrUpdateConsumersMessage) {
this.owningTaskName = checkNotNull(owningTaskName);
this.taskActions = checkNotNull(taskActions);
this.jobId = checkNotNull(jobId);
this.partitionId = checkNotNull(partitionId);
this.partitionType = checkNotNull(partitionType);
this.subpartitions = new ResultSubpartition[numberOfSubpartitions];
this.numTargetKeyGroups = numTargetKeyGroups;
this.partitionManager = checkNotNull(partitionManager);
this.partitionConsumableNotifier = checkNotNull(partitionConsumableNotifier);
this.sendScheduleOrUpdateConsumersMessage = sendScheduleOrUpdateConsumersMessage;
// Create the subpartitions.
switch (partitionType) {
// Batch 模式,SpillableSubpartition,在 Buffer 不充足时将结果写入磁盘
case BLOCKING:
for (int i = 0; i < subpartitions.length; i++) {
subpartitions[i] = new SpillableSubpartition(i, this, ioManager);
}
break;
// Streaming 模式,PipelinedSubpartition
case PIPELINED:
case PIPELINED_BOUNDED:
for (int i = 0; i < subpartitions.length; i++) {
subpartitions[i] = new PipelinedSubpartition(i, this);
}
break;
default:
throw new IllegalArgumentException("Unsupported result partition type.");
}
// Initially, partitions should be consumed once before release.
pin();
LOG.debug("{}: Initialized {}", owningTaskName, this);
}
}
|
Task 启动的时候会向 NetworkEnvironment 进行注册,这里会为每一个 ResultPartition 分配 LocalBufferPool:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
class NetworkEnvironment {
//注册一个Task,要给这个Task的输入和输出分配 buffer pool
public void registerTask(Task task) throws IOException {
final ResultPartition[] producedPartitions = task.getProducedPartitions();
synchronized (lock) {
......
//输出
for (final ResultPartition partition : producedPartitions) {
setupPartition(partition);
}
......
}
}
public void setupPartition(ResultPartition partition) throws IOException {
BufferPool bufferPool = null;
try {
//如果PartitionType 是 unbounded,则不限制buffer pool 的最大大小,否则为 sub-partition * taskmanager.network.memory.buffers-per-channel
int maxNumberOfMemorySegments = partition.getPartitionType().isBounded() ?
partition.getNumberOfSubpartitions() * config.networkBuffersPerChannel() +
config.floatingNetworkBuffersPerGate() : Integer.MAX_VALUE;
// If the partition type is back pressure-free, we register with the buffer pool for
// callbacks to release memory.
//创建一个 LocalBufferPool,请求的最少的 MemeorySegment 数量和 sub-partition 一致
//如果没有反压,则需要自己处理 buffer 的回收(主要是在batch模式)
bufferPool = networkBufferPool.createBufferPool(partition.getNumberOfSubpartitions(),
maxNumberOfMemorySegments,
partition.getPartitionType().hasBackPressure() ? Optional.empty() : Optional.of(partition));
//给这个 ResultPartition 分配 LocalBufferPool
partition.registerBufferPool(bufferPool);
//向 ResultPartitionManager 注册
resultPartitionManager.registerResultPartition(partition);
} catch (Throwable t) {
......
}
}
}
|
Task 通过 RecordWriter 将结果写入 ResultPartition 中。RecordWriter 是对 ResultPartitionWriter 的一层封装,并负责将记录对象序列化到 buffer 中。先来看一下 RecordWriter 的成员变量和构造函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
class RecordWriter {
//底层的 ResultPartition
private final ResultPartitionWriter targetPartition;
//决定一条记录应该写入哪一个channel, 即 sub-partition
private final ChannelSelector<T> channelSelector;
//channel的数量,即 sub-partition的数量
private final int numberOfChannels;
//broadcast记录
private final int[] broadcastChannels;
//序列化
private final RecordSerializer<T> serializer;
//供每一个 channel 写入数据使用
private final Optional<BufferBuilder>[] bufferBuilders;
//定时强制 flush 输出buffer
private final Optional<OutputFlusher> outputFlusher;
RecordWriter(ResultPartitionWriter writer, ChannelSelector<T> channelSelector, long timeout, String taskName) {
this.targetPartition = writer;
this.channelSelector = channelSelector;
this.numberOfChannels = writer.getNumberOfSubpartitions();
this.channelSelector.setup(numberOfChannels);
//序列化器,用于指的一提将一条记录序列化到多个buffer中
this.serializer = new SpanningRecordSerializer<T>();
this.bufferBuilders = new Optional[numberOfChannels];
this.broadcastChannels = new int[numberOfChannels];
for (int i = 0; i < numberOfChannels; i++) {
broadcastChannels[i] = i;
bufferBuilders[i] = Optional.empty();
}
checkArgument(timeout >= -1);
this.flushAlways = (timeout == 0);
if (timeout == -1 || timeout == 0) {
outputFlusher = Optional.empty();
} else {
//根据超时时间创建一个定时 flush 输出 buffer 的线程
String threadName = taskName == null ?
DEFAULT_OUTPUT_FLUSH_THREAD_NAME :
DEFAULT_OUTPUT_FLUSH_THREAD_NAME + " for " + taskName;
outputFlusher = Optional.of(new OutputFlusher(threadName, timeout));
outputFlusher.get().start();
}
}
}
|
当 Task 通过 RecordWriter 输出一条记录时,主要流程为:
- 通过 ChannelSelector 确定写入的目标 channel
- 使用 RecordSerializer 对记录进行序列化
- 向 ResultPartition 请求 BufferBuilder,用于写入序列化结果
- 向 ResultPartition 添加 BufferConsumer,用于读取写入 Buffer 的数据
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
class RecordWriter {
public void emit(T record) throws IOException, InterruptedException {
checkErroneous();
//channelSelector确定目标channel
emit(record, channelSelector.selectChannel(record));
}
private void emit(T record, int targetChannel) throws IOException, InterruptedException {
//序列化
serializer.serializeRecord(record);
//将序列化结果写入buffer
if (copyFromSerializerToTargetChannel(targetChannel)) {
//清除序列化使用的buffer(这个是序列化时临时写入的byte[]),减少内存占用
serializer.prune();
}
}
//将序列化结果写入buffer
private boolean copyFromSerializerToTargetChannel(int targetChannel) throws IOException, InterruptedException {
// We should reset the initial position of the intermediate serialization buffer before
// copying, so the serialization results can be copied to multiple target buffers.
serializer.reset();
boolean pruneTriggered = false;
BufferBuilder bufferBuilder = getBufferBuilder(targetChannel);
SerializationResult result = serializer.copyToBufferBuilder(bufferBuilder);
while (result.isFullBuffer()) {
//buffer 写满了,调用 bufferBuilder.finish 方法
numBytesOut.inc(bufferBuilder.finish());
numBuffersOut.inc();
// If this was a full record, we are done. Not breaking out of the loop at this point
// will lead to another buffer request before breaking out (that would not be a
// problem per se, but it can lead to stalls in the pipeline).
if (result.isFullRecord()) {
//当前这条记录也完整输出了
pruneTriggered = true;
bufferBuilders[targetChannel] = Optional.empty();
break;
}
//当前这条记录没有写完,申请新的 buffer 写入
bufferBuilder = requestNewBufferBuilder(targetChannel);
result = serializer.copyToBufferBuilder(bufferBuilder);
}
checkState(!serializer.hasSerializedData(), "All data should be written at once");
if (flushAlways) {
//强制刷新结果
targetPartition.flush(targetChannel);
}
return pruneTriggered;
}
private BufferBuilder getBufferBuilder(int targetChannel) throws IOException, InterruptedException {
if (bufferBuilders[targetChannel].isPresent()) {
return bufferBuilders[targetChannel].get();
} else {
return requestNewBufferBuilder(targetChannel);
}
}
//请求新的 BufferBuilder,用于写入数据 如果当前没有可用的 buffer,会阻塞
private BufferBuilder requestNewBufferBuilder(int targetChannel) throws IOException, InterruptedException {
checkState(!bufferBuilders[targetChannel].isPresent() || bufferBuilders[targetChannel].get().isFinished());
//从 LocalBufferPool 中请求 BufferBuilder
BufferBuilder bufferBuilder = targetPartition.getBufferProvider().requestBufferBuilderBlocking();
bufferBuilders[targetChannel] = Optional.of(bufferBuilder);
//添加一个BufferConsumer,用于读取写入到 MemorySegment 的数据
targetPartition.addBufferConsumer(bufferBuilder.createBufferConsumer(), targetChannel);
return bufferBuilder;
}
}
|
向 ResultPartition 添加一个 BufferConsumer, ResultPartition 会将其转交给对应的 ResultSubpartition:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
class ResultPartition implement ResultPartitionWriter {
//向指定的 subpartition 添加一个 buffer
@Override
public void addBufferConsumer(BufferConsumer bufferConsumer, int subpartitionIndex) throws IOException {
checkNotNull(bufferConsumer);
ResultSubpartition subpartition;
try {
checkInProduceState();
subpartition = subpartitions[subpartitionIndex];
}
catch (Exception ex) {
bufferConsumer.close();
throw ex;
}
//添加 BufferConsumer,说明已经有数据生成了
if (subpartition.add(bufferConsumer)) {
notifyPipelinedConsumers();
}
}
/**
* Notifies pipelined consumers of this result partition once.
*/
private void notifyPipelinedConsumers() {
//对于 Streaming 模式的任务,由于调度模式为 EAGER,所有的 task 都已经部署了,下面的通知不会触发
if (sendScheduleOrUpdateConsumersMessage && !hasNotifiedPipelinedConsumers && partitionType.isPipelined()) {
//对于 PIPELINE 类型的 ResultPartition,在第一条记录产生时,
//会告知 JobMaster 当前 ResultPartition 可被消费,这会触发下游消费者 Task 的部署
partitionConsumableNotifier.notifyPartitionConsumable(jobId, partitionId, taskActions);
hasNotifiedPipelinedConsumers = true;
}
}
}
|
前面已经看到,根据 ResultPartitionType 的不同,ResultSubpartition 的实现类也不同。对于 Streaming 模式,使用的是 PipelinedSubpartition :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
public abstract class ResultSubpartition {
/** The index of the subpartition at the parent partition. */
protected final int index;
/** The parent partition this subpartition belongs to. */
protected final ResultPartition parent;
/** All buffers of this subpartition. Access to the buffers is synchronized on this object. */
//当前 subpartiion 堆积的所有的 Buffer 的队列
protected final ArrayDeque<BufferConsumer> buffers = new ArrayDeque<>();
/** The number of non-event buffers currently in this subpartition. */
//当前 subpartiion 中堆积的 buffer 的数量
@GuardedBy("buffers")
private int buffersInBacklog;
}
class PipelinedSubpartition extends ResultSubpartition {
//用于消费写入的 Buffer
private PipelinedSubpartitionView readView;
//index 是当前 sub-paritition 的索引
PipelinedSubpartition(int index, ResultPartition parent) {
super(index, parent);
}
@Override
public boolean add(BufferConsumer bufferConsumer) {
return add(bufferConsumer, false);
}
//添加一个新的BufferConsumer
//这个参数里的 finish 指的是整个 subpartition 都完成了
private boolean add(BufferConsumer bufferConsumer, boolean finish) {
checkNotNull(bufferConsumer);
final boolean notifyDataAvailable;
synchronized (buffers) {
if (isFinished || isReleased) {
bufferConsumer.close();
return false;
}
// Add the bufferConsumer and update the stats
buffers.add(bufferConsumer);
updateStatistics(bufferConsumer);
//更新 backlog 的数量,只有 buffer 才会使得 buffersInBacklog + 1,事件不会增加 buffersInBacklog
increaseBuffersInBacklog(bufferConsumer);
notifyDataAvailable = shouldNotifyDataAvailable() || finish;
isFinished |= finish;
}
if (notifyDataAvailable) {
//通知数据可以被消费
notifyDataAvailable();
}
return true;
}
//只在第一个 buffer 为 finish 的时候才通知
private boolean shouldNotifyDataAvailable() {
// Notify only when we added first finished buffer.
return readView != null && !flushRequested && getNumberOfFinishedBuffers() == 1;
}
//通知readView,有数据可用了
private void notifyDataAvailable() {
if (readView != null) {
readView.notifyDataAvailable();
}
}
@Override
public void flush() {
final boolean notifyDataAvailable;
synchronized (buffers) {
if (buffers.isEmpty()) {
return;
}
// if there is more then 1 buffer, we already notified the reader
// (at the latest when adding the second buffer)
notifyDataAvailable = !flushRequested && buffers.size() == 1;
flushRequested = true;
}
if (notifyDataAvailable) {
notifyDataAvailable();
}
}
}
|
在强制进行 flush 的时候,也会发出数据可用的通知。这是因为,假如产出的数据记录较少无法完整地填充一个 MemorySegment,那么 ResultSubpartition 可能会一直处于不可被消费的状态。而为了保证产出的记录能够及时被消费,就需要及时进行 flush,从而确保下游能更及时地处理数据。在 RecordWriter 中有一个 OutputFlusher 会定时触发 flush,间隔可以通过 DataStream.setBufferTimeout() 来控制。
写入的 Buffer 最终被保存在 ResultSubpartition 中维护的一个队列中,如果需要消费这些 Buffer,就需要依赖 ResultSubpartitionView。当需要消费一个 ResultSubpartition 的结果时,需要创建一个 ResultSubpartitionView 对象,并关联到 ResultSubpartition 中;当数据可以被消费时,会通过对应的回调接口告知 ResultSubpartitionView:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
|
/**
* A view to consume a {@link ResultSubpartition} instance.
*/
public interface ResultSubpartitionView {
/**
* Returns the next {@link Buffer} instance of this queue iterator.
*
* <p>If there is currently no instance available, it will return <code>null</code>.
* This might happen for example when a pipelined queue producer is slower
* than the consumer or a spilled queue needs to read in more data.
*
* <p><strong>Important</strong>: The consumer has to make sure that each
* buffer instance will eventually be recycled with {@link Buffer#recycleBuffer()}
* after it has been consumed.
*/
@Nullable
BufferAndBacklog getNextBuffer() throws IOException, InterruptedException;
//通知 ResultSubpartition 的数据可供消费
void notifyDataAvailable();
//已经完成对 ResultSubpartition 的消费
void notifySubpartitionConsumed() throws IOException;
boolean nextBufferIsEvent();
//........
}
class PipelinedSubpartitionView implements ResultSubpartitionView {
/** The subpartition this view belongs to. */
private final PipelinedSubpartition parent;
private final BufferAvailabilityListener availabilityListener;
/** Flag indicating whether this view has been released. */
private final AtomicBoolean isReleased;
PipelinedSubpartitionView(PipelinedSubpartition parent, BufferAvailabilityListener listener) {
this.parent = checkNotNull(parent);
this.availabilityListener = checkNotNull(listener);
this.isReleased = new AtomicBoolean();
}
@Nullable
@Override
public BufferAndBacklog getNextBuffer() {
return parent.pollBuffer();
}
@Override
public void notifyDataAvailable() {
//回调接口
availabilityListener.notifyDataAvailable();
}
@Override
public void notifySubpartitionConsumed() {
releaseAllResources();
}
@Override
public void releaseAllResources() {
if (isReleased.compareAndSet(false, true)) {
// The view doesn't hold any resources and the parent cannot be restarted. Therefore,
// it's OK to notify about consumption as well.
parent.onConsumedSubpartition();
}
}
@Override
public boolean isReleased() {
return isReleased.get() || parent.isReleased();
}
@Override
public boolean nextBufferIsEvent() {
return parent.nextBufferIsEvent();
}
@Override
public boolean isAvailable() {
return parent.isAvailable();
}
}
|
当需要创建一个 ResultSubpartition 的消费者时,需要通过 ResultPartitionManager 来创建。ResultPartitionManager 会管理当前 Task 的所有 ResultPartition。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
class ResultPartitionManager implements ResultPartitionProvider {
//管理所有的 ResultPartition,使用的时 Guava 提供的支持多级映射的哈希表
public final Table<ExecutionAttemptID, IntermediateResultPartitionID, ResultPartition>
registeredPartitions = HashBasedTable.create();
//一个 Task 在向 NetworkEnvironment 注册的时候就会逐一注册所有的ResultPartition
public void registerResultPartition(ResultPartition partition) throws IOException {
synchronized (registeredPartitions) {
checkState(!isShutdown, "Result partition manager already shut down.");
ResultPartitionID partitionId = partition.getPartitionId();
ResultPartition previous = registeredPartitions.put(
partitionId.getProducerId(), partitionId.getPartitionId(), partition);
if (previous != null) {
throw new IllegalStateException("Result partition already registered.");
}
LOG.debug("Registered {}.", partition);
}
}
//在指定的 ResultSubpartition 中创建一个 ResultSubpartitionView,用于消费数据
@Override
public ResultSubpartitionView createSubpartitionView(
ResultPartitionID partitionId,
int subpartitionIndex,
BufferAvailabilityListener availabilityListener) throws IOException {
synchronized (registeredPartitions) {
final ResultPartition partition = registeredPartitions.get(partitionId.getProducerId(),
partitionId.getPartitionId());
//创建 ResultSubpartitionView,可以看作是 ResultSubpartition 的消费者
return partition.createSubpartitionView(subpartitionIndex, availabilityListener);
}
}
}
|
至此,我们已经了解了一个 Task 如何输出结果到 ResultPartition 中,以及如何去消费不同 ResultSubpartition 中的这些用于保存序列化结果的 Buffer。
Task 的输入
在了解了 Task 如何输出结果以后,接下来我们把目光投向 Task 的输入端。
前面已经介绍过,Task 的输入被抽象为 InputGate, 而 InputGate 则由 InputChannel 组成, InputChannel 和该 Task 需要消费的 ResultSubpartition 是一一对应的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
public interface InputGate extends AutoCloseable {
int getNumberOfInputChannels();
String getOwningTaskName();
boolean isFinished();
//请求消费 ResultPartition
void requestPartitions() throws IOException, InterruptedException;
/**
* Blocking call waiting for next {@link BufferOrEvent}.
* 阻塞调用
* @return {@code Optional.empty()} if {@link #isFinished()} returns true.
*/
Optional<BufferOrEvent> getNextBufferOrEvent() throws IOException, InterruptedException;
/**
* Poll the {@link BufferOrEvent}.
* 非阻塞调用
* @return {@code Optional.empty()} if there is no data to return or if {@link #isFinished()} returns true.
*/
Optional<BufferOrEvent> pollNextBufferOrEvent() throws IOException, InterruptedException;
void sendTaskEvent(TaskEvent event) throws IOException;
void registerListener(InputGateListener listener);
int getPageSize();
}
|
Task 通过循环调用 InputGate.getNextBufferOrEvent 方法获取输入数据,并将获取的数据交给它所封装的算子进行处理,这构成了一个 Task 的基本运行逻辑。 InputGate 有两个具体的实现,分别为 SingleInputGate 和 UnionInputGate, UnionInputGate 有多个 SingleInputGate 联合构成。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
|
class SingleInputGate {
//该 InputGate 包含的所有 InputChannel
private final Map<IntermediateResultPartitionID, InputChannel> inputChannels;
/** Channels, which notified this input gate about available data. */
//InputChannel 构成的队列,这些 InputChannel 中都有有可供消费的数据
private final ArrayDeque<InputChannel> inputChannelsWithData = new ArrayDeque<>();
/**
* Buffer pool for incoming buffers. Incoming data from remote channels is copied to buffers
* from this pool.
*/
//用于接收输入的缓冲池
private BufferPool bufferPool;
/** Global network buffer pool to request and recycle exclusive buffers (only for credit-based). */
//全局网络缓冲池
private NetworkBufferPool networkBufferPool;
/** Registered listener to forward buffer notifications to. */
private volatile InputGateListener inputGateListener;
private Optional<BufferOrEvent> getNextBufferOrEvent(boolean blocking) throws IOException, InterruptedException {
if (hasReceivedAllEndOfPartitionEvents) {
return Optional.empty();
}
if (isReleased) {
throw new IllegalStateException("Released");
}
//首先尝试请求分区,实际的请求只会执行一次
requestPartitions();
InputChannel currentChannel;
boolean moreAvailable;
Optional<BufferAndAvailability> result = Optional.empty();
do {
synchronized (inputChannelsWithData) {
//从 inputChannelsWithData 队列中获取有数据的 channel,经典的生产者-消费者模式
while (inputChannelsWithData.size() == 0) {
if (isReleased) {
throw new IllegalStateException("Released");
}
if (blocking) {
inputChannelsWithData.wait();
}
else {
return Optional.empty();
}
}
currentChannel = inputChannelsWithData.remove();
enqueuedInputChannelsWithData.clear(currentChannel.getChannelIndex());
//是否还有更多的数据
moreAvailable = !inputChannelsWithData.isEmpty();
}
result = currentChannel.getNextBuffer();
} while (!result.isPresent());
// this channel was now removed from the non-empty channels queue
// we re-add it in case it has more data, because in that case no "non-empty" notification
// will come for that channel
if (result.get().moreAvailable()) {
//如果这个channel还有更多的数据,继续加入到队列中
queueChannel(currentChannel);
moreAvailable = true;
}
final Buffer buffer = result.get().buffer();
if (buffer.isBuffer()) {
return Optional.of(new BufferOrEvent(buffer, currentChannel.getChannelIndex(), moreAvailable));
}
else {
final AbstractEvent event = EventSerializer.fromBuffer(buffer, getClass().getClassLoader());
//如果是 EndOfPartitionEvent 事件,那么如果所有的 InputChannel 都接收到这个事件了
//将 hasReceivedAllEndOfPartitionEvents 标记为 true,此后不再能获取到数据
if (event.getClass() == EndOfPartitionEvent.class) {
channelsWithEndOfPartitionEvents.set(currentChannel.getChannelIndex());
if (channelsWithEndOfPartitionEvents.cardinality() == numberOfInputChannels) {
// Because of race condition between:
// 1. releasing inputChannelsWithData lock in this method and reaching this place
// 2. empty data notification that re-enqueues a channel
// we can end up with moreAvailable flag set to true, while we expect no more data.
checkState(!moreAvailable || !pollNextBufferOrEvent().isPresent());
moreAvailable = false;
hasReceivedAllEndOfPartitionEvents = true;
}
currentChannel.notifySubpartitionConsumed();
currentChannel.releaseAllResources();
}
return Optional.of(new BufferOrEvent(event, currentChannel.getChannelIndex(), moreAvailable));
}
}
//当一个 InputChannel 有数据时的回调
void notifyChannelNonEmpty(InputChannel channel) {
queueChannel(checkNotNull(channel));
}
//将新的channel加入队列
private void queueChannel(InputChannel channel) {
int availableChannels;
synchronized (inputChannelsWithData) {
//判断这个channel是否已经在队列中
if (enqueuedInputChannelsWithData.get(channel.getChannelIndex())) {
return;
}
availableChannels = inputChannelsWithData.size();
//加入队列
inputChannelsWithData.add(channel);
enqueuedInputChannelsWithData.set(channel.getChannelIndex());
if (availableChannels == 0) {
//如果之前队列中没有channel,这个channel加入后,通知等待的线程
inputChannelsWithData.notifyAll();
}
}
if (availableChannels == 0) {
//如果之前队列中没有channel,这个channel加入后,通知InputGateListener
//表明这个 InputGate 中有数据了
InputGateListener listener = inputGateListener;
if (listener != null) {
listener.notifyInputGateNonEmpty(this);
}
}
}
//请求分区
@Override
public void requestPartitions() throws IOException, InterruptedException {
synchronized (requestLock) {
//只请求一次
if (!requestedPartitionsFlag) {
if (isReleased) {
throw new IllegalStateException("Already released.");
}
// Sanity checks
if (numberOfInputChannels != inputChannels.size()) {
throw new IllegalStateException("Bug in input gate setup logic: mismatch between " +
"number of total input channels and the currently set number of input " +
"channels.");
}
for (InputChannel inputChannel : inputChannels.values()) {
//每一个channel都请求对应的子分区
inputChannel.requestSubpartition(consumedSubpartitionIndex);
}
}
requestedPartitionsFlag = true;
}
}
}
|
SingleInputGate 的逻辑还比较清晰,它通过内部维护的一个队列形成一个生产者-消费者的模型,当 InputChannel 中有数据时就加入到队列中,在需要获取数据时从队列中取出一个 channel,获取 channel 中的数据。
UnionInputGate 时多个 SingleInputGate 联合组成,它的内部有一个 inputGatesWithData 队列:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
public class UnionInputGate implements InputGate, InputGateListener {
/** The input gates to union. */
private final InputGate[] inputGates;
/** Gates, which notified this input gate about available data. */
private final ArrayDeque<InputGate> inputGatesWithData = new ArrayDeque<>();
@Override
public Optional<BufferOrEvent> getNextBufferOrEvent() throws IOException, InterruptedException {
if (inputGatesWithRemainingData.isEmpty()) {
return Optional.empty();
}
// Make sure to request the partitions, if they have not been requested before.
requestPartitions();
InputGateWithData inputGateWithData = waitAndGetNextInputGate();
InputGate inputGate = inputGateWithData.inputGate;
BufferOrEvent bufferOrEvent = inputGateWithData.bufferOrEvent;
if (bufferOrEvent.moreAvailable()) {
//这个 InputGate 中还有更多的数据,继续加入队列
// this buffer or event was now removed from the non-empty gates queue
// we re-add it in case it has more data, because in that case no "non-empty" notification
// will come for that gate
queueInputGate(inputGate);
}
if (bufferOrEvent.isEvent()
&& bufferOrEvent.getEvent().getClass() == EndOfPartitionEvent.class
&& inputGate.isFinished()) {
checkState(!bufferOrEvent.moreAvailable());
if (!inputGatesWithRemainingData.remove(inputGate)) {
throw new IllegalStateException("Couldn't find input gate in set of remaining " +
"input gates.");
}
}
// Set the channel index to identify the input channel (across all unioned input gates)
final int channelIndexOffset = inputGateToIndexOffsetMap.get(inputGate);
bufferOrEvent.setChannelIndex(channelIndexOffset + bufferOrEvent.getChannelIndex());
bufferOrEvent.setMoreAvailable(bufferOrEvent.moreAvailable() || inputGateWithData.moreInputGatesAvailable);
return Optional.of(bufferOrEvent);
}
private InputGateWithData waitAndGetNextInputGate() throws IOException, InterruptedException {
while (true) {
InputGate inputGate;
boolean moreInputGatesAvailable;
synchronized (inputGatesWithData) {
//等待 inputGatesWithData 队列,经典的生产者-消费者模型
while (inputGatesWithData.size() == 0) {
inputGatesWithData.wait();
}
inputGate = inputGatesWithData.remove();
enqueuedInputGatesWithData.remove(inputGate);
moreInputGatesAvailable = enqueuedInputGatesWithData.size() > 0;
}
// In case of inputGatesWithData being inaccurate do not block on an empty inputGate, but just poll the data.
Optional<BufferOrEvent> bufferOrEvent = inputGate.pollNextBufferOrEvent();
if (bufferOrEvent.isPresent()) {
return new InputGateWithData(inputGate, bufferOrEvent.get(), moreInputGatesAvailable);
}
}
}
@Override
public void notifyInputGateNonEmpty(InputGate inputGate) {
queueInputGate(checkNotNull(inputGate));
}
}
|
InputGate 相当于是对 InputChannel 的一层封装,实际数据的获取还是要依赖于 InputChannel。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public abstract class InputChannel {
protected final int channelIndex;
//消费的目标 ResultPartitionID
protected final ResultPartitionID partitionId;
protected final SingleInputGate inputGate;
//回调函数,告知 InputGate 当前 channel 有数据
protected void notifyChannelNonEmpty() {
inputGate.notifyChannelNonEmpty(this);
}
//请求ResultSubpartition
abstract void requestSubpartition(int subpartitionIndex) throws IOException, InterruptedException;
abstract Optional<BufferAndAvailability> getNextBuffer() throws IOException, InterruptedException;
abstract void sendTaskEvent(TaskEvent event) throws IOException;
abstract void notifySubpartitionConsumed() throws IOException;
abstract void releaseAllResources() throws IOException;
}
|
InputChannel 的基本逻辑也比较简单,它的生命周期按照 requestSubpartition(int subpartitionIndex), getNextBuffer() 和 releaseAllResources() 这样的顺序进行。
根据 InputChannel 消费的 ResultPartition 的位置,InputChannel 有 LocalInputChannel 和 RemoteInputChannel 两中不同的实现,分别对应本地和远程数据交换。我们将在接下来两节分别进行分析。InputChannel 还有一个实现类是 UnknownInputChannel,相当于是还未确定 ResultPartition 位置的情况下的占位符,最终还是会更新为 LocalInputChannel 或是 RemoteInputChannel。
本地数据交换
如果一个 InputChannel 和其消费的上游 ResultPartition 所属 Task 都在同一个 TaskManager 中运行,那么它们之间的数据交换就在同一个 JVM 进程内不同线程之间进行,无需通过网络交换。我们已经了解到,ResultSubpartition 中的 buffer 可以通过 ResultSubpartitionView 进行消费。LocalInputChannel 正是
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
|
public class LocalInputChannel extends InputChannel implements BufferAvailabilityListener {
/** The local partition manager. */
private final ResultPartitionManager partitionManager;
/** Task event dispatcher for backwards events. */
private final TaskEventPublisher taskEventPublisher;
/** The consumed subpartition. */
private volatile ResultSubpartitionView subpartitionView;
//请求消费对应的子分区
@Override
void requestSubpartition(int subpartitionIndex) throws IOException, InterruptedException {
boolean retriggerRequest = false;
// The lock is required to request only once in the presence of retriggered requests.
synchronized (requestLock) {
checkState(!isReleased, "LocalInputChannel has been released already");
if (subpartitionView == null) {
try {
//Local,无需网络通信,通过 ResultPartitionManager 创建一个 ResultSubpartitionView
//LocalInputChannel 实现了 BufferAvailabilityListener
//在有数据时会得到通知,notifyDataAvailable 会被调用,进而将当前 channel 加到 InputGate 的可用 Channel 队列中
ResultSubpartitionView subpartitionView = partitionManager.createSubpartitionView(
partitionId, subpartitionIndex, this);
if (subpartitionView == null) {
throw new IOException("Error requesting subpartition.");
}
// make the subpartition view visible
this.subpartitionView = subpartitionView;
// check if the channel was released in the meantime
if (isReleased) {
subpartitionView.releaseAllResources();
this.subpartitionView = null;
}
} catch (PartitionNotFoundException notFound) {
if (increaseBackoff()) {
retriggerRequest = true;
} else {
throw notFound;
}
}
}
}
// Do this outside of the lock scope as this might lead to a
// deadlock with a concurrent release of the channel via the
// input gate.
if (retriggerRequest) {
inputGate.retriggerPartitionRequest(partitionId.getPartitionId());
}
}
//读取数据,借助 ResultSubparitionView 消费 ResultSubparition 中的苏剧
@Override
Optional<BufferAndAvailability> getNextBuffer() throws IOException, InterruptedException {
checkError();
ResultSubpartitionView subpartitionView = this.subpartitionView;
if (subpartitionView == null) {
// There is a possible race condition between writing a EndOfPartitionEvent (1) and flushing (3) the Local
// channel on the sender side, and reading EndOfPartitionEvent (2) and processing flush notification (4). When
// they happen in that order (1 - 2 - 3 - 4), flush notification can re-enqueue LocalInputChannel after (or
// during) it was released during reading the EndOfPartitionEvent (2).
if (isReleased) {
return Optional.empty();
}
// this can happen if the request for the partition was triggered asynchronously
// by the time trigger
// would be good to avoid that, by guaranteeing that the requestPartition() and
// getNextBuffer() always come from the same thread
// we could do that by letting the timer insert a special "requesting channel" into the input gate's queue
subpartitionView = checkAndWaitForSubpartitionView();
}
//通过 ResultSubparitionView 获取
BufferAndBacklog next = subpartitionView.getNextBuffer();
if (next == null) {
if (subpartitionView.isReleased()) {
throw new CancelTaskException("Consumed partition " + subpartitionView + " has been released.");
} else {
return Optional.empty();
}
}
numBytesIn.inc(next.buffer().getSizeUnsafe());
numBuffersIn.inc();
return Optional.of(new BufferAndAvailability(next.buffer(), next.isMoreAvailable(), next.buffersInBacklog()));
}
//回调,在 ResultSubparition 通知 ResultSubparitionView 有数据可供消费,
@Override
public void notifyDataAvailable() {
//LocalInputChannel 通知 InputGate
notifyChannelNonEmpty();
}
@Override
void sendTaskEvent(TaskEvent event) throws IOException {
checkError();
checkState(subpartitionView != null, "Tried to send task event to producer before requesting the subpartition.");
//事件分发
if (!taskEventPublisher.publish(partitionId, event)) {
throw new IOException("Error while publishing event " + event + " to producer. The producer could not be found.");
}
}
}
|
这里的逻辑相对比较简单,LocalInputChannel 实现了 InputChannel 接口,同时也实现了 BufferAvailabilityListener 接口。LocalInputChannel 通过 ResultPartitionManager 请求创建和指定 ResultSubparition 关联的 ResultSubparitionView,并以自身作为 ResultSubparitionView 的回调。这样,一旦 ResultSubparition 有数据产出时,ResultSubparitionView 会得到通知,同时 LocalInputChannel 的回调函数也会被调用,这样消费者这一端就可以及时获取到数据的生产情况,从而及时地去消费数据。
通过网络进行数据交换
网络栈
在 Flink 中,不同 Task 之间的网络传输基于 Netty 实现。NetworkEnvironment 中通过 ConnectionManager 来管理所有的网络的连接,而 NettyConnectionManager 就是 ConnectionManager 的具体实现。
NettyConnectionManager 在启动的时候会创建并启动 NettyClient 和 NettyServer,NettyServer 会启动一个服务端监听,等待其它 NettyClient 的连接:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
public class NettyConnectionManager implements ConnectionManager {
private final NettyServer server;
private final NettyClient client;
private final NettyBufferPool bufferPool;
private final PartitionRequestClientFactory partitionRequestClientFactory;
private final boolean isCreditBased;
@Override
public void start(ResultPartitionProvider partitionProvider, TaskEventPublisher taskEventPublisher) throws IOException {
NettyProtocol partitionRequestProtocol = new NettyProtocol(partitionProvider, taskEventPublisher, isCreditBased);
//初始化 Netty Client
client.init(partitionRequestProtocol, bufferPool);
//初始化并启动 Netty Server
server.init(partitionRequestProtocol, bufferPool);
}
}
|
NettyProtocal 中提供了 NettyClient 和 NettyServer 引导启动注册的一系列 Channel Handler,这些 Handler 的主要逻辑在后面再进行详细分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public class NettyProtocol {
public ChannelHandler[] getServerChannelHandlers() {
//netty server 端的 ChannelHandler
PartitionRequestQueue queueOfPartitionQueues = new PartitionRequestQueue();
PartitionRequestServerHandler serverHandler = new PartitionRequestServerHandler(
partitionProvider, taskEventPublisher, queueOfPartitionQueues, creditBasedEnabled);
return new ChannelHandler[] {
messageEncoder,
new NettyMessage.NettyMessageDecoder(!creditBasedEnabled),
serverHandler,
queueOfPartitionQueues
};
}
public ChannelHandler[] getClientChannelHandlers() {
//netty client 端的 ChannelHandler
NetworkClientHandler networkClientHandler =
creditBasedEnabled ? new CreditBasedPartitionRequestClientHandler() :
new PartitionRequestClientHandler();
return new ChannelHandler[] {
messageEncoder,
new NettyMessage.NettyMessageDecoder(!creditBasedEnabled),
networkClientHandler};
}
}
|
值得一提的是, NettyServer 在启动的时候会配置水位线,如果 Netty 输出缓冲中的字节数超过了高水位值,我们会等到其降到低水位值以下才继续写入数据。通过水位线机制确保不往网络中写入太多数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
class NettyServer {
void init(final NettyProtocol protocol, NettyBufferPool nettyBufferPool) throws IOException {
......
final int newLowWaterMark = config.getMemorySegmentSize() + 1;
final int newHighWaterMark = 2 * config.getMemorySegmentSize();
//配置水位线,确保不往网络中写入太多数据
//当输出缓冲中的字节数超过高水位值, 则 Channel.isWritable() 会返回false
//当输出缓存中的字节数低于低水位值, 则 Channel.isWritable() 会重新返回true
bootstrap.childOption(ChannelOption.WRITE_BUFFER_HIGH_WATER_MARK, newHighWaterMark);
bootstrap.childOption(ChannelOption.WRITE_BUFFER_LOW_WATER_MARK, newLowWaterMark);
}
}
|
当 RemoteInputChannel 请求一个远端的 ResultSubpartition 的时候,NettyClient 就会发起和请求的 ResultSubpartition 所在 Task 的 NettyServer 的连接,后续所有的数据交换都在这个连接上进行。两个 Task 之间只会建立一个连接,这个连接会在不同的 RemoteInputChannel 和 ResultSubpartition 之间进行复用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
public class NettyConnectionManager implements ConnectionManager {
@Override
public PartitionRequestClient createPartitionRequestClient(ConnectionID connectionId)
throws IOException, InterruptedException {
//这里实际上会建立和其它 Task 的 Server 的连接
//返回的 PartitionRequestClient 中封装了 netty channel 和 channel handler
return partitionRequestClientFactory.createPartitionRequestClient(connectionId);
}
}
class PartitionRequestClientFactory {
private final NettyClient nettyClient;
private final ConcurrentMap<ConnectionID, Object> clients = new ConcurrentHashMap<ConnectionID, Object>();
PartitionRequestClient createPartitionRequestClient(ConnectionID connectionId) throws IOException, InterruptedException {
Object entry;
PartitionRequestClient client = null;
while (client == null) {
entry = clients.get(connectionId);
if (entry != null) {
//连接已经建立
// Existing channel or connecting channel
if (entry instanceof PartitionRequestClient) {
client = (PartitionRequestClient) entry;
} else {
ConnectingChannel future = (ConnectingChannel) entry;
client = future.waitForChannel();
clients.replace(connectionId, future, client);
}
}
else {
// No channel yet. Create one, but watch out for a race.
// We create a "connecting future" and atomically add it to the map.
// Only the thread that really added it establishes the channel.
// The others need to wait on that original establisher's future.
// 连接创建成功后会回调 handInChannel 方法
ConnectingChannel connectingChannel = new ConnectingChannel(connectionId, this);
Object old = clients.putIfAbsent(connectionId, connectingChannel);
if (old == null) {
//连接到 Netty Server
nettyClient.connect(connectionId.getAddress()).addListener(connectingChannel);
client = connectingChannel.waitForChannel();
clients.replace(connectionId, connectingChannel, client);
} else if (old instanceof ConnectingChannel) {
client = ((ConnectingChannel) old).waitForChannel();
clients.replace(connectionId, old, client);
} else {
client = (PartitionRequestClient) old;
}
}
// Make sure to increment the reference count before handing a client
// out to ensure correct bookkeeping for channel closing.
if (!client.incrementReferenceCounter()) {
destroyPartitionRequestClient(connectionId, client);
client = null;
}
}
return client;
}
}
|
另外,Flink Buffer 的实现类 NetworkBuffer 直接继承了 Netty 的 AbstractReferenceCountedByteBuf,这样使得 Netty 可以直接使用 Flink 的 Buffer,从而避免了在 Flink Buffers 和 Netty Buffers 之间的数据拷贝:
1
2
3
4
5
6
7
8
9
10
|
public class NetworkBuffer extends AbstractReferenceCountedByteBuf implements Buffer {
private final MemorySegment memorySegment;
//......
@Override
protected void deallocate() {
//回收当前buffer, LocalBufferPool 实现了 BufferRecycler 接口
recycler.recycle(memorySegment);
}
}
|
流量控制
Flink 在两个 Task 之间建立 Netty 连接进行数据传输,每一个 Task 会分配两个缓冲池,一个用于输出数据,一个用于接收数据。当一个 Task 的缓冲池用尽之后,网络连接就处于阻塞状态,上游 Task 无法产出数据,下游 Task 无法接收数据,也就是我们所说的“反压”状态。这是一种非常自然的“反压”的机制,但是过程也相对比较粗暴。由于 TaskManager 之间的网络连接是由不同 Task 复用的,一旦网络处于阻塞状态,所有 Task 都无法向 TCP 连接中写入数据或者从中读取数据,即便其它 Task 关联的缓冲池仍然存在空余。此外,由于网络发生了阻塞,诸如 CheckpointBarrier 等事件也无法在 Task 之间进行流转。
为了解决上述问题,Flink 1.5 重构了网络栈,引入了“基于信用值的流量控制算法”(Credit-based Flow Control),确保 TaskManager 之间的网络连接始终不会处于阻塞状态。Credit-based Flow Control 的思路其实也比较简单,它是在接收端和发送端之间建立一种类似“信用评级”的机制,发送端向接收端发送的数据永远不会超过接收端的信用值的大小。在 Flink 这里,信用值就是接收端可用的 Buffer 的数量,这样就可以保证发送端不会向 TCP 连接中发送超出接收端缓冲区可用容量的数据。
相比于之前所有的 InputChannel 共享同一个本地缓冲池的方式,在重构网络栈之后,Flink 会为每一个 InputChannel 分配一批独占的缓冲(exclusive buffers),而本地缓冲池中的 buffer 则作为流动的(floating buffers),可以被所有的 InputChannel 使用。
Credit-based Flow Control 的具体机制为:
- 接收端向发送端声明可用的 Credit(一个可用的 buffer 对应一点 credit);
- 当发送端获得了 X 点 Credit,表明它可以向网络中发送 X 个 buffer;当接收端分配了 X 点 Credit 给发送端,表明它有 X 个空闲的 buffer 可以接收数据;
- 只有在 Credit > 0 的情况下发送端才发送 buffer;发送端每发送一个 buffer,Credit 也相应地减少一点
- 由于
CheckpointBarrier,EndOfPartitionEvent 等事件可以被立即处理,因而事件可以立即发送,无需使用 Credit
- 当发送端发送 buffer 的时候,它同样把当前堆积的 buffer 数量(backlog size)告知接收端;接收端根据发送端堆积的数量来申请 floating buffer
这种流量控制机制可以有效地改善网络的利用率,不会因为 buffer 长时间停留在网络链路中进而导致整个所有的 Task 都无法继续处理数据,也无法进行 Checkpoint 操作。但是它的一个潜在的缺点是增加了上下游之间的通信成本(需要发送 credit 和 backlog 信息)。在目前的版本中可以通过 taskmanager.network.credit-model: false 来禁用,但后续应该会移除这个配置项。
具体实现
在了解了 Flink 的网络栈和流量控制机制后,下面我们就来具体看一下 Flink 是如何在不同 Task 之间通过网络进行数据交换的。
初始化
首先,在向 NetworkEnvironment 注册的时候,会为 InputGate 分配本地缓冲池,还会为 RemoteInputChannel 分配独占的 buffer:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
class NetworkEnvironment {
public void setupInputGate(SingleInputGate gate) throws IOException {
BufferPool bufferPool = null;
int maxNumberOfMemorySegments;
try {
if (config.isCreditBased()) { //使用 Credit-based Flow Control
//本地缓冲池使用的 buffer 数量,如果是 bounded,则缓冲池的大小最大为 taskmanager.network.memory.floating-buffers-per-gate
maxNumberOfMemorySegments = gate.getConsumedPartitionType().isBounded() ?
config.floatingNetworkBuffersPerGate() : Integer.MAX_VALUE;
// assign exclusive buffers to input channels directly and use the rest for floating buffers
// 独占的buffer,不包含在分配的 LocalBufferPool 中
gate.assignExclusiveSegments(networkBufferPool, config.networkBuffersPerChannel());
bufferPool = networkBufferPool.createBufferPool(0, maxNumberOfMemorySegments);
} else {
maxNumberOfMemorySegments = gate.getConsumedPartitionType().isBounded() ?
gate.getNumberOfInputChannels() * config.networkBuffersPerChannel() +
config.floatingNetworkBuffersPerGate() : Integer.MAX_VALUE;
bufferPool = networkBufferPool.createBufferPool(gate.getNumberOfInputChannels(),
maxNumberOfMemorySegments);
}
//分配 LocalBufferPool 本地缓冲池,这是所有 channel 共享的
gate.setBufferPool(bufferPool);
} catch (Throwable t) {
if (bufferPool != null) {
bufferPool.lazyDestroy();
}
ExceptionUtils.rethrowIOException(t);
}
}
}
class SingleInputGate {
public void assignExclusiveSegments(NetworkBufferPool networkBufferPool, int networkBuffersPerChannel) throws IOException {
checkState(this.isCreditBased, "Bug in input gate setup logic: exclusive buffers only exist with credit-based flow control.");
checkState(this.networkBufferPool == null, "Bug in input gate setup logic: global buffer pool has" +
"already been set for this input gate.");
this.networkBufferPool = checkNotNull(networkBufferPool);
this.networkBuffersPerChannel = networkBuffersPerChannel;
synchronized (requestLock) {
for (InputChannel inputChannel : inputChannels.values()) {
if (inputChannel instanceof RemoteInputChannel) {
//RemoteInputChannel 请求独占的 buffer
((RemoteInputChannel) inputChannel).assignExclusiveSegments(
networkBufferPool.requestMemorySegments(networkBuffersPerChannel));
}
}
}
}
}
|
在 RemoteInputChannel 内部使用 AvailableBufferQueue 来管理所有可用的 buffer:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
|
class RemoteInputChannel extends InputChannel implements BufferRecycler, BufferListener {
//可用的 buffer 队列,包含 exclusive + floating
/** The available buffer queue wraps both exclusive and requested floating buffers. */
private final AvailableBufferQueue bufferQueue = new AvailableBufferQueue();
//分配独占的 buffer
void assignExclusiveSegments(List<MemorySegment> segments) {
this.initialCredit = segments.size();
this.numRequiredBuffers = segments.size();
synchronized (bufferQueue) {
for (MemorySegment segment : segments) {
//注意这个 NetworkBuffer 的回收器是 RemoteInputChannel 自身
bufferQueue.addExclusiveBuffer(new NetworkBuffer(segment, this), numRequiredBuffers);
}
}
}
//独占的 buffer 释放后会直接被 RemoteInputChannel 回收
@Override
public void recycle(MemorySegment segment) {
int numAddedBuffers;
synchronized (bufferQueue) {
// Similar to notifyBufferAvailable(), make sure that we never add a buffer
// after releaseAllResources() released all buffers (see below for details).
if (isReleased.get()) {
//如果这个 channle 已经被释放
try {
//这个 MemorySegment 会被归还给 NetworkBufferPool
inputGate.returnExclusiveSegments(Collections.singletonList(segment));
return;
} catch (Throwable t) {
ExceptionUtils.rethrow(t);
}
}
//重新加入到 AvailableBufferQueue 中
numAddedBuffers = bufferQueue.addExclusiveBuffer(new NetworkBuffer(segment, this), numRequiredBuffers);
}
if (numAddedBuffers > 0 && unannouncedCredit.getAndAdd(numAddedBuffers) == 0) {
notifyCreditAvailable();
}
}
/**
* Manages the exclusive and floating buffers of this channel, and handles the
* internal buffer related logic.
*/
private static class AvailableBufferQueue {
//这部分是流动的
private final ArrayDeque<Buffer> floatingBuffers;
//这部分是独占的
private final ArrayDeque<Buffer> exclusiveBuffers;
AvailableBufferQueue() {
this.exclusiveBuffers = new ArrayDeque<>();
this.floatingBuffers = new ArrayDeque<>();
}
//添加一个独占的buffer,如果当前可用的 buffer 总量超出了要求的数量,则向本地缓冲池归还一个流动的buffer
//返回值是新增的 buffer 数量
int addExclusiveBuffer(Buffer buffer, int numRequiredBuffers) {
exclusiveBuffers.add(buffer);
if (getAvailableBufferSize() > numRequiredBuffers) {
Buffer floatingBuffer = floatingBuffers.poll();
floatingBuffer.recycleBuffer();
//加一个,归还一个,相当于没加
return 0;
} else {
return 1;
}
}
//添加一个流动的buffer
void addFloatingBuffer(Buffer buffer) {
floatingBuffers.add(buffer);
}
//优先取流动的buffer
@Nullable
Buffer takeBuffer() {
if (floatingBuffers.size() > 0) {
return floatingBuffers.poll();
} else {
return exclusiveBuffers.poll();
}
}
int getAvailableBufferSize() {
return floatingBuffers.size() + exclusiveBuffers.size();
}
}
}
|
请求远端子分区
RemoteInputChannel 请求远端的 ResultSubpartition,会创建一个 PartitionRequestClient,并通过 Netty 发送 PartitionRequest 请求,这时会带上当前 InputChannel 的 id 和初始的 credit 信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
class RemoteInputChannel extends InputChannel implements BufferRecycler, BufferListener {
public void requestSubpartition(int subpartitionIndex) throws IOException, InterruptedException {
//REMOTE,需要网络通信,使用 Netty 建立网络
//通过 ConnectionManager 来建立连接:创建 PartitionRequestClient,通过 PartitionRequestClient 发起请求
if (partitionRequestClient == null) {
// Create a client and request the partition
partitionRequestClient = connectionManager
.createPartitionRequestClient(connectionId);
//请求分区,通过 netty 发起请求
partitionRequestClient.requestSubpartition(partitionId, subpartitionIndex, this, 0);
}
}
}
public class PartitionRequestClient {
public ChannelFuture requestSubpartition(
final ResultPartitionID partitionId,
final int subpartitionIndex,
final RemoteInputChannel inputChannel,
int delayMs) throws IOException {
//向 NetworkClientHandler 注册当前 RemoteInputChannel
//单个 Task 所有的 RemoteInputChannel 的数据传输都通过这个 PartitionRequestClient 处理
clientHandler.addInputChannel(inputChannel);
//PartitionRequest封装了请求的 sub-partition 的信息,当前 input channel 的 ID,以及初始 credit
final PartitionRequest request = new PartitionRequest(
partitionId, subpartitionIndex, inputChannel.getInputChannelId(), inputChannel.getInitialCredit());
final ChannelFutureListener listener = new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
if (!future.isSuccess()) {
//如果请求发送失败,要移除当前的 inputChannel
clientHandler.removeInputChannel(inputChannel);
SocketAddress remoteAddr = future.channel().remoteAddress();
inputChannel.onError(
new LocalTransportException(
String.format("Sending the partition request to '%s' failed.", remoteAddr),
future.channel().localAddress(), future.cause()
));
}
}
};
//通过 netty 发送请求
if (delayMs == 0) {
ChannelFuture f = tcpChannel.writeAndFlush(request);
f.addListener(listener);
return f;
} else {
final ChannelFuture[] f = new ChannelFuture[1];
tcpChannel.eventLoop().schedule(new Runnable() {
@Override
public void run() {
f[0] = tcpChannel.writeAndFlush(request);
f[0].addListener(listener);
}
}, delayMs, TimeUnit.MILLISECONDS);
return f[0];
}
}
}
|
生产端的处理流程
生产者端即 ResultSubpartition 一侧,在网络通信中对应 NettyServer。NettyServer 有两个重要的 ChannelHandler,即 PartitionRequestServerHandler 和 PartitionRequestQueue。其中,PartitionRequestServerHandler 负责处理消费端通过 PartitionRequestClient 发送的 PartitionRequest 和 AddCredit 等请求;PartitionRequestQueue 则包含了一个可以从中读取数据的 NetworkSequenceViewReader 队列,它会监听 Netty Channel 的可写入状态,一旦可以写入数据,就会从 NetworkSequenceViewReader 消费数据写入 Netty Channel。
首先,当 NettyServer 接收到 PartitionRequest 消息后,PartitionRequestServerHandler 会创建一个 NetworkSequenceViewReader 对象,请求创建 ResultSubpartitionView, 并将 NetworkSequenceViewReader 保存在 PartitionRequestQueue 中。PartitionRequestQueue 会持有所有请求消费数据的 RemoteInputChannel 的 ID 和 NetworkSequenceViewReader 之间的映射关系。
我们已经知道,ResultSubpartitionView 用来消费 ResultSubpartition 中的数据,并在 ResultSubpartition 中有数据可用时获得提醒;NetworkSequenceViewReader 则相当于对 ResultSubpartition 的一层包装,她会按顺序为读取的每一个 buffer 分配一个序列号,并且记录了接收数据的 RemoteInputChannel 的 ID。在使用 Credit-based Flow Control 的情况下,NetworkSequenceViewReader 的具体实现对应为 CreditBasedSequenceNumberingViewReader。 CreditBasedSequenceNumberingViewReader 同时还实现了 BufferAvailabilityListener 接口,因而可以作为 PipelinedSubpartitionView 的回调对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
|
class PartitionRequestServerHandler extends SimpleChannelInboundHandler<NettyMessage> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, NettyMessage msg) throws Exception {
try {
Class<?> msgClazz = msg.getClass();
if (msgClazz == PartitionRequest.class) {
//Server 端接收到 client 发送的 PartitionRequest
PartitionRequest request = (PartitionRequest) msg;
try {
NetworkSequenceViewReader reader;
if (creditBasedEnabled) {
reader = new CreditBasedSequenceNumberingViewReader(
request.receiverId,
request.credit,
outboundQueue);
} else {
reader = new SequenceNumberingViewReader(
request.receiverId,
outboundQueue);
}
//通过 ResultPartitionProvider(实际上就是 ResultPartitionManager)创建 ResultSubpartitionView
//在有可被消费的数据产生后,PartitionRequestQueue.notifyReaderNonEmpty 会被回调,进而在 netty channelPipeline 上触发一次 fireUserEventTriggered
reader.requestSubpartitionView(
partitionProvider,
request.partitionId,
request.queueIndex);
//通知 PartitionRequestQueue 创建了一个 NetworkSequenceViewReader
outboundQueue.notifyReaderCreated(reader);
} catch (PartitionNotFoundException notFound) {
respondWithError(ctx, notFound, request.receiverId);
}
}
......
} catch (Throwable t) {
respondWithError(ctx, t);
}
}
}
class CreditBasedSequenceNumberingViewReader implements BufferAvailabilityListener, NetworkSequenceViewReader {
private final InputChannelID receiverId; //对应的 RemoteInputChannel 的 ID
private final PartitionRequestQueue requestQueue;
//消费 ResultSubpartition 的数据,并在 ResultSubpartition 有数据可用时获得通知
private volatile ResultSubpartitionView subpartitionView;
//numCreditsAvailable的值是消费端还能够容纳的buffer的数量,也就是允许生产端发送的buffer的数量
private int numCreditsAvailable;
private int sequenceNumber = -1; //序列号,自增
//创建一个 ResultSubpartitionView,用于读取数据,并在有数据可用时获得通知
@Override
public void requestSubpartitionView(
ResultPartitionProvider partitionProvider,
ResultPartitionID resultPartitionId,
int subPartitionIndex) throws IOException {
synchronized (requestLock) {
if (subpartitionView == null) {
this.subpartitionView = partitionProvider.createSubpartitionView(
resultPartitionId,
subPartitionIndex,
this);
} else {
throw new IllegalStateException("Subpartition already requested");
}
}
}
//读取数据
@Override
public BufferAndAvailability getNextBuffer() throws IOException, InterruptedException {
BufferAndBacklog next = subpartitionView.getNextBuffer(); //读取数据
if (next != null) {
sequenceNumber++; //序列号
//要发送一个buffer,对应的 numCreditsAvailable 要减 1
if (next.buffer().isBuffer() && --numCreditsAvailable < 0) {
throw new IllegalStateException("no credit available");
}
return new BufferAndAvailability(
next.buffer(), isAvailable(next), next.buffersInBacklog());
} else {
return null;
}
}
//是否还可以消费数据:
// 1. ResultSubpartition 中有更多的数据
// 2. credit > 0 或者下一条数据是事件(事件不需要消耗credit)
@Override
public boolean isAvailable() {
// BEWARE: this must be in sync with #isAvailable(BufferAndBacklog)!
return hasBuffersAvailable() &&
//要求 numCreditsAvailable > 0 或者是 Event
(numCreditsAvailable > 0 || subpartitionView.nextBufferIsEvent());
}
boolean hasBuffersAvailable() {
return subpartitionView.isAvailable();
}
//和上面 isAvailable() 是等价的
private boolean isAvailable(BufferAndBacklog bufferAndBacklog) {
// BEWARE: this must be in sync with #isAvailable()!
return bufferAndBacklog.isMoreAvailable() &&
(numCreditsAvailable > 0 || bufferAndBacklog.nextBufferIsEvent());
}
//在 ResultSubparition 中有数据时会回调该方法
@Override
public void notifyDataAvailable() {
//告知 PartitionRequestQueue 当前 ViewReader 有数据可读
requestQueue.notifyReaderNonEmpty(this);
}
}
|
PartitionRequestQueue 负责将 ResultSubparition 中的数据通过网络发送给 RemoteInputChannel。在 PartitionRequestQueue 中保存了所有的 NetworkSequenceViewReader 和 InputChannelID 之间的映射关系,以及一个 ArrayDeque<NetworkSequenceViewReader> availableReaders 队列。当一个 NetworkSequenceViewReader 中有数据可以被消费时,就会被加入到 availableReaders 队列中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
class PartitionRequestQueue extends ChannelInboundHandlerAdapter {
/** The readers which are already enqueued available for transferring data. */
private final ArrayDeque<NetworkSequenceViewReader> availableReaders = new ArrayDeque<>();
/** All the readers created for the consumers' partition requests. */
private final ConcurrentMap<InputChannelID, NetworkSequenceViewReader> allReaders = new ConcurrentHashMap<>();
//添加新的 NetworkSequenceViewReader
public void notifyReaderCreated(final NetworkSequenceViewReader reader) {
allReaders.put(reader.getReceiverId(), reader);
}
//通知 NetworkSequenceViewReader 有数据可读取
void notifyReaderNonEmpty(final NetworkSequenceViewReader reader) {
//触发一次用户自定义事件
ctx.executor().execute(() -> ctx.pipeline().fireUserEventTriggered(reader));
}
//自定义用户事件的处理
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object msg) throws Exception {
// The user event triggered event loop callback is used for thread-safe
// hand over of reader queues and cancelled producers.
if (msg instanceof NetworkSequenceViewReader) {
//NetworkSequenceViewReader有数据可读取,加入队列中
enqueueAvailableReader((NetworkSequenceViewReader) msg);
} else if (msg.getClass() == InputChannelID.class) {
// 对应的 RemoteInputChannel 请求取消消费
// Release partition view that get a cancel request.
InputChannelID toCancel = (InputChannelID) msg;
if (released.contains(toCancel)) {
return;
}
// Cancel the request for the input channel
int size = availableReaders.size();
for (int i = 0; i < size; i++) {
NetworkSequenceViewReader reader = pollAvailableReader();
if (reader.getReceiverId().equals(toCancel)) {
reader.releaseAllResources();
markAsReleased(reader.getReceiverId());
} else {
registerAvailableReader(reader);
}
}
allReaders.remove(toCancel);
} else {
ctx.fireUserEventTriggered(msg);
}
}
//加入队列
private void enqueueAvailableReader(final NetworkSequenceViewReader reader) throws Exception {
if (reader.isRegisteredAsAvailable() || !reader.isAvailable()) {
//已经被注册到队列中,或者暂时没有 buffer 或没有 credit 可用
return;
}
boolean triggerWrite = availableReaders.isEmpty();
registerAvailableReader(reader);
if (triggerWrite) {
//如果这是队列中第一个元素,调用 writeAndFlushNextMessageIfPossible 发送数据
writeAndFlushNextMessageIfPossible(ctx.channel());
}
}
}
|
PartitionRequestQueue 会监听 Netty Channel 的可写入状态,当 Channel 可写入时,就会从 availableReaders 队列中取出 NetworkSequenceViewReader,读取数据并写入网络。可写入状态是 Netty 通过水位线进行控制的,NettyServer 在启动的时候会配置水位线,如果 Netty 输出缓冲中的字节数超过了高水位值,我们会等到其降到低水位值以下才继续写入数据。通过水位线机制确保不往网络中写入太多数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
|
class PartitionRequestQueue extends ChannelInboundHandlerAdapter {
@Override
public void channelWritabilityChanged(ChannelHandlerContext ctx) throws Exception {
//当前channel的读写状态发生变化
writeAndFlushNextMessageIfPossible(ctx.channel());
}
private void writeAndFlushNextMessageIfPossible(final Channel channel) throws IOException {
if (fatalError || !channel.isWritable()) {
//如果当前不可写入,则直接返回
return;
}
BufferAndAvailability next = null;
try {
while (true) {
//取出一个 reader
NetworkSequenceViewReader reader = pollAvailableReader();
if (reader == null) {
return;
}
next = reader.getNextBuffer();
if (next == null) {
//没有读到数据
if (!reader.isReleased()) {
//还没有释放当前 subpartition,继续处理下一个 reader
continue;
}
markAsReleased(reader.getReceiverId());
//出错了
Throwable cause = reader.getFailureCause();
if (cause != null) {
ErrorResponse msg = new ErrorResponse(
new ProducerFailedException(cause),
reader.getReceiverId());
ctx.writeAndFlush(msg);
}
} else {
// 读到了数据
if (next.moreAvailable()) {
//这个 reader 还可以读到更多的数据,继续加入队列
registerAvailableReader(reader);
}
BufferResponse msg = new BufferResponse(
next.buffer(),
reader.getSequenceNumber(),
reader.getReceiverId(),
next.buffersInBacklog());
// 向 client 发送数据,发送成功之后通过 writeListener 的回调触发下一次发送
channel.writeAndFlush(msg).addListener(writeListener);
return;
}
}
} catch (Throwable t) {
if (next != null) {
next.buffer().recycleBuffer();
}
throw new IOException(t.getMessage(), t);
}
}
private class WriteAndFlushNextMessageIfPossibleListener implements ChannelFutureListener {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
try {
if (future.isSuccess()) {
//发送成功,再次尝试写入
writeAndFlushNextMessageIfPossible(future.channel());
} else if (future.cause() != null) {
handleException(future.channel(), future.cause());
} else {
handleException(future.channel(), new IllegalStateException("Sending cancelled by user."));
}
} catch (Throwable t) {
handleException(future.channel(), t);
}
}
}
}
|
在 Credit-based Flow Control 算法中,每发送一个 buffer 就会消耗一点 credit,在消费端有空闲 buffer 可用时会发送 AddCrdit 消息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
class PartitionRequestServerHandler extends SimpleChannelInboundHandler<NettyMessage> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, NettyMessage msg) throws Exception {
......
if (msgClazz == AddCredit.class) {
//增加 credit
AddCredit request = (AddCredit) msg;
outboundQueue.addCredit(request.receiverId, request.credit);
}
......
}
}
class RequestReaderQueue extends ChannelInboundHandlerAdapter {
void addCredit(InputChannelID receiverId, int credit) throws Exception {
if (fatalError) {
return;
}
NetworkSequenceViewReader reader = allReaders.get(receiverId);
if (reader != null) {
//增加 credit
reader.addCredit(credit);
//因为增加了credit,可能可以继续处理数据,因此把 reader 加入队列
enqueueAvailableReader(reader);
} else {
throw new IllegalStateException("No reader for receiverId = " + receiverId + " exists.");
}
}
}
|
消费端处理流程
消费端即 RemoteInputChannel 一侧,在网络通信中对应 NettyClient。同样地,我们从 ChannelHandler 作为入口进行分析。
1
2
3
4
5
6
7
|
public interface NetworkClientHandler extends ChannelHandler {
void addInputChannel(RemoteInputChannel inputChannel) throws IOException;
void removeInputChannel(RemoteInputChannel inputChannel);
void cancelRequestFor(InputChannelID inputChannelId);
//通知有新的的 credit 可用
void notifyCreditAvailable(final RemoteInputChannel inputChannel);
}
|
NetworkClientHanlder 对应的实现类为 CreditBasedPartitionRequestClientHandler,CreditBasedPartitionRequestClientHandler 负责接收服务端通过 Netty channel 发送的数据,解析数据后交给对应的 RemoteInputChannle 进行处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
|
class CreditBasedPartitionRequestClientHandler extends ChannelInboundHandlerAdapter implements NetworkClientHandler {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//从netty channel中接收到数据
try {
//解析消息
decodeMsg(msg);
} catch (Throwable t) {
notifyAllChannelsOfErrorAndClose(t);
}
}
private void decodeMsg(Object msg) throws Throwable {
final Class<?> msgClazz = msg.getClass();
// ---- Buffer --------------------------------------------------------
if (msgClazz == NettyMessage.BufferResponse.class) {
//正常的数据
NettyMessage.BufferResponse bufferOrEvent = (NettyMessage.BufferResponse) msg;
//根据 ID 定位到对应的 RemoteInputChannel
RemoteInputChannel inputChannel = inputChannels.get(bufferOrEvent.receiverId);
if (inputChannel == null) {
//如果没有对应的 RemoteInputChannel
bufferOrEvent.releaseBuffer();
//取消对给定 receiverId 的订阅
cancelRequestFor(bufferOrEvent.receiverId);
return;
}
//解析消息,是buffer还是event
decodeBufferOrEvent(inputChannel, bufferOrEvent);
} else if (msgClazz == NettyMessage.ErrorResponse.class) {
// ---- Error ---------------------------------------------------------
......
} else {
throw new IllegalStateException("Received unknown message from producer: " + msg.getClass());
}
}
private void decodeBufferOrEvent(RemoteInputChannel inputChannel, NettyMessage.BufferResponse bufferOrEvent) throws Throwable {
try {
ByteBuf nettyBuffer = bufferOrEvent.getNettyBuffer();
final int receivedSize = nettyBuffer.readableBytes();
if (bufferOrEvent.isBuffer()) {
// ---- Buffer ------------------------------------------------
// Early return for empty buffers. Otherwise Netty's readBytes() throws an
// IndexOutOfBoundsException.
if (receivedSize == 0) {
inputChannel.onEmptyBuffer(bufferOrEvent.sequenceNumber, bufferOrEvent.backlog);
return;
}
//从对应的 RemoteInputChannel 中请求一个 Buffer
Buffer buffer = inputChannel.requestBuffer();
if (buffer != null) {
//将接收的数据写入buffer
nettyBuffer.readBytes(buffer.asByteBuf(), receivedSize);
//通知对应的channel,backlog是生产者那边堆积的buffer数量
inputChannel.onBuffer(buffer, bufferOrEvent.sequenceNumber, bufferOrEvent.backlog);
} else if (inputChannel.isReleased()) {
cancelRequestFor(bufferOrEvent.receiverId);
} else {
throw new IllegalStateException("No buffer available in credit-based input channel.");
}
} else {
// ---- Event -------------------------------------------------
// TODO We can just keep the serialized data in the Netty buffer and release it later at the reader
byte[] byteArray = new byte[receivedSize];
nettyBuffer.readBytes(byteArray);
MemorySegment memSeg = MemorySegmentFactory.wrap(byteArray);
//是一个事件,不需要从 RemoteInputChannel 中申请 buffer
Buffer buffer = new NetworkBuffer(memSeg, FreeingBufferRecycler.INSTANCE, false, receivedSize);
//通知对应的channel,backlog是生产者那边堆积的buffer数量
inputChannel.onBuffer(buffer, bufferOrEvent.sequenceNumber, bufferOrEvent.backlog);
}
} finally {
bufferOrEvent.releaseBuffer();
}
}
}
|
CreditBasedPartitionRequestClientHandler 从网络中读取数据后交给 RemoteInputChannel, RemoteInputChannel 会将接收到的加入队列中,并根据生产端的堆积申请 floating buffer:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
|
public class RemoteInputChannel extends InputChannel implements BufferRecycler, BufferListener {
//接收到远程 ResultSubpartition 发送的 Buffer
public void onBuffer(Buffer buffer, int sequenceNumber, int backlog) throws IOException {
boolean recycleBuffer = true;
try {
final boolean wasEmpty;
synchronized (receivedBuffers) {
if (isReleased.get()) {
return;
}
//序号需要匹配
if (expectedSequenceNumber != sequenceNumber) {
onError(new BufferReorderingException(expectedSequenceNumber, sequenceNumber));
return;
}
//加入 receivedBuffers 队列中
wasEmpty = receivedBuffers.isEmpty();
receivedBuffers.add(buffer);
recycleBuffer = false;
}
++expectedSequenceNumber;
if (wasEmpty) {
//通知 InputGate,当前 channel 有新数据
notifyChannelNonEmpty();
}
if (backlog >= 0) {
//根据客户端的积压申请float buffer
onSenderBacklog(backlog);
}
} finally {
if (recycleBuffer) {
buffer.recycleBuffer();
}
}
}
//backlog 是发送端的堆积 的 buffer 数量,
//如果 bufferQueue 中 buffer 的数量不足,就去须从 LocalBufferPool 中请求 floating buffer
//在请求了新的 buffer 后,通知生产者有 credit 可用
void onSenderBacklog(int backlog) throws IOException {
int numRequestedBuffers = 0;
synchronized (bufferQueue) {
// Similar to notifyBufferAvailable(), make sure that we never add a buffer
// after releaseAllResources() released all buffers (see above for details).
if (isReleased.get()) {
return;
}
//需要的 buffer 数量是 backlog + initialCredit, backlog 是生产者当前的积压
numRequiredBuffers = backlog + initialCredit;
while (bufferQueue.getAvailableBufferSize() < numRequiredBuffers && !isWaitingForFloatingBuffers) {
//不停地请求新的 floating buffer
Buffer buffer = inputGate.getBufferPool().requestBuffer();
if (buffer != null) {
//从 buffer poll 中请求到 buffer
bufferQueue.addFloatingBuffer(buffer);
numRequestedBuffers++;
} else if (inputGate.getBufferProvider().addBufferListener(this)) {
// buffer pool 没有 buffer 了,加一个监听,当 LocalBufferPool 中有新的 buffer 时会回调 notifyBufferAvailable
// If the channel has not got enough buffers, register it as listener to wait for more floating buffers.
isWaitingForFloatingBuffers = true;
break;
}
}
}
if (numRequestedBuffers > 0 && unannouncedCredit.getAndAdd(numRequestedBuffers) == 0) {
//请求了新的floating buffer,要更新 credit
notifyCreditAvailable();
}
}
private void notifyCreditAvailable() {
checkState(partitionRequestClient != null, "Tried to send task event to producer before requesting a queue.");
//通知当前 channel 有新的 credit
partitionRequestClient.notifyCreditAvailable(this);
}
//LocalBufferPool 通知有 buffer 可用
@Override
public NotificationResult notifyBufferAvailable(Buffer buffer) {
NotificationResult notificationResult = NotificationResult.BUFFER_NOT_USED;
try {
synchronized (bufferQueue) {
checkState(isWaitingForFloatingBuffers,
"This channel should be waiting for floating buffers.");
// Important: make sure that we never add a buffer after releaseAllResources()
// released all buffers. Following scenarios exist:
// 1) releaseAllResources() already released buffers inside bufferQueue
// -> then isReleased is set correctly
// 2) releaseAllResources() did not yet release buffers from bufferQueue
// -> we may or may not have set isReleased yet but will always wait for the
// lock on bufferQueue to release buffers
if (isReleased.get() || bufferQueue.getAvailableBufferSize() >= numRequiredBuffers) {
isWaitingForFloatingBuffers = false;
return notificationResult;
}
//增加floating buffer
bufferQueue.addFloatingBuffer(buffer);
if (bufferQueue.getAvailableBufferSize() == numRequiredBuffers) {
//bufferQueue中有足够多的 buffer 了
isWaitingForFloatingBuffers = false;
notificationResult = NotificationResult.BUFFER_USED_NO_NEED_MORE;
} else {
//bufferQueue 中 buffer 仍然不足
notificationResult = NotificationResult.BUFFER_USED_NEED_MORE;
}
}
if (unannouncedCredit.getAndAdd(1) == 0) {
notifyCreditAvailable();
}
} catch (Throwable t) {
setError(t);
}
return notificationResult;
}
}
|
一旦 RemoteInputChannel 申请到新的 buffer,就需要通知生产者更新 credit,这需要发送一条 AddCredit 消息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
|
class PartitionRequestClient {
//交给 NetworkClientHandler 处理
public void notifyCreditAvailable(RemoteInputChannel inputChannel) {
clientHandler.notifyCreditAvailable(inputChannel);
}
}
class CreditBasedPartitionRequestClientHandler extends ChannelInboundHandlerAdapter implements NetworkClientHandler {
//有新的credit
@Override
public void notifyCreditAvailable(final RemoteInputChannel inputChannel) {
//触发一次自定义事件
ctx.executor().execute(() -> ctx.pipeline().fireUserEventTriggered(inputChannel));
}
@Override
public void channelWritabilityChanged(ChannelHandlerContext ctx) throws Exception {
writeAndFlushNextMessageIfPossible(ctx.channel());
}
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object msg) throws Exception {
if (msg instanceof RemoteInputChannel) {
//有新的credit会触发
boolean triggerWrite = inputChannelsWithCredit.isEmpty();
//加入到队列中
inputChannelsWithCredit.add((RemoteInputChannel) msg);
if (triggerWrite) {
writeAndFlushNextMessageIfPossible(ctx.channel());
}
} else {
ctx.fireUserEventTriggered(msg);
}
}
private void writeAndFlushNextMessageIfPossible(Channel channel) {
if (channelError.get() != null || !channel.isWritable()) {
return;
}
//从队列中取出 RemoteInputChannel, 发送消息
while (true) {
RemoteInputChannel inputChannel = inputChannelsWithCredit.poll();
// The input channel may be null because of the write callbacks
// that are executed after each write.
if (inputChannel == null) {
return;
}
//It is no need to notify credit for the released channel.
if (!inputChannel.isReleased()) {
//发送 AddCredit 的消息
AddCredit msg = new AddCredit(
inputChannel.getPartitionId(),
inputChannel.getAndResetUnannouncedCredit(), //获取并重置新增的credit
inputChannel.getInputChannelId());
// Write and flush and wait until this is done before
// trying to continue with the next input channel.
channel.writeAndFlush(msg).addListener(writeListener);
return;
}
}
}
private class WriteAndFlushNextMessageIfPossibleListener implements ChannelFutureListener {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
try {
if (future.isSuccess()) {
writeAndFlushNextMessageIfPossible(future.channel());
} else if (future.cause() != null) {
notifyAllChannelsOfErrorAndClose(future.cause());
} else {
notifyAllChannelsOfErrorAndClose(new IllegalStateException("Sending cancelled by user."));
}
} catch (Throwable t) {
notifyAllChannelsOfErrorAndClose(t);
}
}
}
}
|
反压
在上面几节,我们已经详细地分析了 Task 之间的数据交换机制和它们的实现原理,理解这这些实际上就已经理解了 Flink 的“反压”机制。
所谓“反压”,就是指在流处理系统中,下游任务的处理速度跟不上上游任务的数据生产速度。许多日常问题都会导致反压,例如,垃圾回收停顿可能会导致流入的数据快速堆积,或者遇到大促或秒杀活动导致流量陡增。反压如果不能得到正确的处理,可能会导致资源耗尽甚至系统崩溃。反压机制就是指系统能够自己检测到被阻塞的算子,然后系统自适应地降低源头或者上游的发送速率。在 Flink 中,应对“反压”是一种极其自然的方式,因为 Flink 中的数据传输机制已经提供了应对反压的措施。
在本地数据交换的情况下,两个 Task 实际上是同一个 JVM 中的两个线程,Task1 产生的 Buffer 直接被 Task2 使用,当 Task2 处理完之后这个 Buffer 就会被回收到本地缓冲池中。一旦 Task2 的处理速度比 Task2 产生 Buffer 的速度慢,那么缓冲池中 Buffer 渐渐地就会被耗尽,Task1 无法申请到新的 Buffer 自然就会阻塞,因而会导致 Task1 的降速。
在网络数据交换的情况下,如果下游 Task 的处理速度较慢,下游 Task 的接收缓冲池逐渐耗尽后就无法从网络中读取新的数据,这回导致上游 Task 无法将缓冲池中的 Buffer 发送到网络中,因此上游 Task 的缓冲池也会被耗尽,进而导致上游任务的降速。为了解决网络连接阻塞导致所有 Task 都无法处理数据的情况,Flink 还引入了 Credit-based Flow Control 算法,在上游生产者下游消费只之间通过“信用点”来协调发送速度,确保网络连接永远不会被阻塞。同时,Flink 的网络栈基于 Netty 构建,通过 Netty 的水位线机制也可以控制发送端的发送速率。
小结
本文详细地分析在 Flink 作业中,不同的 Task 之间是如何进行数据交换的。我们先介绍了 Flink 数据交换机制的整体流程,然后分别对本地数据交换和网络数据交换的情况进行了细致的分析。在最后,我们也概括了 Flink 是如何应对“背压”的。总的来说,通过合理地利用缓冲池和流量控制算法,Flink 可以高效地在不同 Task 之间进行数据传输,并优雅地达到了自适应调整速度效果。
参考
-EOF-