Aloha:一个分布式任务调度框架
文章目录
概览
Aloha 是一个基于 Scala 实现的分布式的任务调度和管理框架,提供插件式扩展功能,可以用来调度各种类型的任务。Aloha 的典型的应用场景是作为统一的任务管理入口。例如,在数据平台上通常会运行各种类型的应用,如 Spark 任务,Flink 任务,ETL 任务等,统一对这些任务进行管理并及时感知任务状态的变化是很有必要的。
Aloha 的基本实现是基于 Spark 的任务调度模块,在 Master 和 Worker 组件的基础上进行了修改,并提供了扩展接口,可以方便地集成各种类型的任务。Master 支持高可用配置及状态恢复,并提供了 REST 接口用于提交任务。
扩展
不同类型应用程序
在 Aloha 中,调度的应用被抽象为 Application 接口。只需要按需实现 Application 接口,就可以对多种不同类型的应用进行调度管理。Application 的生命周期主要通过 start(), shutdown() 进行管理,当应用被调度到 worker 上执行时, start() 方法首先被调用,当用户要求强制停止应用时,shutdown() 方法被调用。
|
|
你可能注意到了,start() 方法的返回值是一个 Promise 对象。这是因为,Aloha 最初在设计时主要针对的是长期运行的应用程序,如 Flink 任务、Spark Streaming 任务等。对于这一类 long-running 的应用,Future 和 Promise 提供了一种更灵活的任务状态通知机制。当任务停止后,通过调用 Promise.success() 方法告知 Worker。
例如,如果要通过启动一个独立进程的方式来启动一个应用程序,可以这样来实现:
|
|
自定义事件监听
在很多情况下,我们希望能够实时感知到任务状态的变化,例如在任务完成或者失败时发送一条消息提醒。Aloha 提供了事件监听接口,可以及时对任务状态的变化作出响应。
|
|
自定义实现的事件监听器在 Aloha 启动时动态注册,也可以同时注册多个监听器。
模块设计
总体架构
Aloha 的整体实现方案是建构在 Spark 的基础之上,因而 Aloha 也是基于主从架构实现的,主要由 Master 和 Worker 这两个主要组件构成:Master 负责管理集群中所有的 Worker,接收用户提交的应用,并将应用分派给不同的 Worker;而 Worker 主要是负责启动、关闭具体的应用,对应用的生命周期进行管理等。Aloha 还提供了 REST 服务,实际上充当了 Client 的角色,方便通过 REST 接口提交应用。
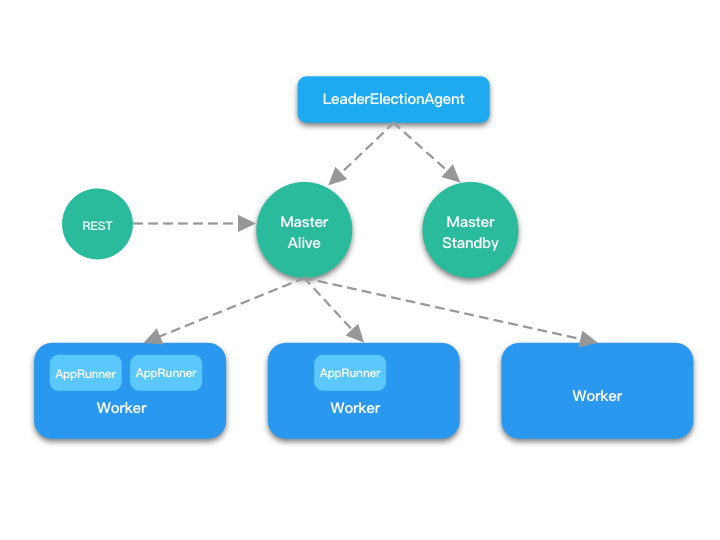 Aloha 提供了 HA 配置,在 Master 发生故障时可以自动进行故障转移。同时启动的多个 Master 实例,只有一个实例会处于 Alive 状态,其余的处于 Standby 状态。当原本处于 Alive 状态的 Master 实例宕机后,LeaderElectionAgent 会从处于 Standby 状态的 Master 中选举出新的 Alive Master,并恢复故障之前的状态。
Aloha 提供了 HA 配置,在 Master 发生故障时可以自动进行故障转移。同时启动的多个 Master 实例,只有一个实例会处于 Alive 状态,其余的处于 Standby 状态。当原本处于 Alive 状态的 Master 实例宕机后,LeaderElectionAgent 会从处于 Standby 状态的 Master 中选举出新的 Alive Master,并恢复故障之前的状态。
任务调度管理
Worker 注册
在 Master 启动后,等待 Worker 的注册请求。在 Worker 启动时,根据 Master 的地址向 Master 发送注册请求。由于可能会有多个 Master 实例在运行,Worker 会所有的这些Master 都发送注册请求,只有处于 Alive 状态的 Master 会响应注册成功的消息,处于Standby 状态的 Master 会告知 Worker 自己正处于 Standby 状态,Worker 会忽略这一类消息。Worker 会一直尝试向 Master 发送注册请求,直到接收到注册成功的响应。在向 Master 发送注册请求时,请求的消息中会包含当前 Worker 节点的计算资源信息,包括可用的 CPU 数量和内存大小,Master 在进行调度的时候会追踪 Worker 的资源使用情况。
一旦 Worker 注册成功,就会周期性地向 Master 发送心跳信息。Master 则会定期检查所有 Worker 的心跳情况,一旦发现太久没有接收到某一个 Worker 的心跳消息,则认为该 Worker 已经下线。另外,网络故障或者进程异常退出等情况会造成 Master 和 Worker 之间建立的网络连接断开,连接断开的事件能直接被 Master 和 Worker 监听到。对 Master 而言,一旦一个 Worker 掉线,需要将该 Worker 上运行的应用置为为异常状态,或是重新调度这些应用。对于 Worker 而言,一旦失去和 Master 建立的连接,就需要重新进入注册流程。
Application 提交
可以通过两种方式向 Master 提交 Application,一种方式是通过 REST 接口,另一种方式是自行创建一个 Client,通过 Master 的地址向 Master 发送 RPC 调用。实际上 REST Server 充当了一个 Client 的角色。
当 Master 接收到注册 Application 的请求时,会分配 applicationId,并将应用放到等待调度的列表中。在调度时,采用 FIFO 的方式,选取剩余资源能够满足应用需求的 Worker,向对应的 Worker 发送启动应用的消息,应用从 SUMITTED 状态切换为 LAUNCHING 状态。Worker 在收到启动的应用的请求后,会为对应的应用创建工作目录,并为每一个应用单独启动一个工作线程。应用成功启动后会向 Master 发送应用状态改变的消息,应用状态切换为 RUNNING 状态。此后每当应用状态发生改变,例如任务成功完成,或是异常退出,都会向 Master 发送应用状态改变的消息。在应用启动后,对于的工作线程会阻塞地等待应用结束。当 Master 接收到强制停止应用的请求后,会将消息转发给对应的 Worker,Worker 在接收到消息后会中断对应应用的工作线程,工作线程响应中断,调用 Application 提供的强制关闭方法强行停止应用。
为了支持扩展不同的应用,Worker 在启动应用时使用了自定义的 ClassLoader 去加载应用提供的依赖包和配置文件路径。目前需要预先在每个 Worker 上放置好对应的文件,并在提交应用时指定路径。后续可以考虑使用一个分布式文件系统,如 HDFS ,在启动应用前下载对应的依赖,或者用户提交应用时上传依赖文件,以避免预先放置文件的不便。由于每个应用的依赖文件都是单独进行加载的,用户可以方便地对应用进行升级,同时也避免了不同 Application 出现依赖冲突的问题。
容错机制
由于 Master 负责对整个集群的应用的调度情况进行管理,一旦 Master 出现异常,则整个集群就处于瘫痪的状态,因而必须要考虑为 Master 提供异常恢复机制。
Master 的异常恢复机制的核心流程在于状态的恢复。Master 会将已经注册的 Worker 和 Application的状态信息持久化存储在持久化引擎中(目前支持 FileSystem 和 ZooKeeper,支持扩展),每当 Worker 或者 Application 的状态发生更改,都会更新存储引擎中保存的状态。当 Master 启动时,处于 Standby 状态。一旦 Master 被选举为 Alive 节点,首先要从存储引擎中读取 Worker 和 Application 的状态信息,如果没有历史状态,则 Master 可以变更为 Alive 状态,否则进入恢复流程,状态变更为 RECOVERING。在恢复流程中,首先要检查 Application 的状态,如果 Application 还没有被调度到任何 Worker 上,则 Application 被放入调度队列,否则将 Application 的状态置为 ApplicationState.UNKNOWN。随后检查所有 Worker 的状态,将 Worker 置为 WorkerState.UNKNOWN 状态,并尝试向 Worker 发送 MasterChange 的消息。在 Worker 接收到 MasterChange 的消息后,会向 Master 响应目前该 Worker 上运行的所有 Application 的状态,Master 接收到响应后就可以将对应的 Worker 和 Application 分别调整为 WorkerState.ALIVE 和 ApplicationState.RUNNING。对于超时仍没有得到响应的 Worker 和 Application,则认为已经掉线或异常退出。至此,状态恢复完成,Master 进入 ALIVE 状态,可以正常处理 Worker 和 Application 的各种请求。
在使用 Standalone 模式时,可以使用 FILESYSTEM 作为存储引擎,这种情况下只有一个 Master 会运行,失败后需要手动进行重启,重启后状态可以恢复。也可以将 Master 配置为 HA 模式,多个 Master 实例同时运行,使用 ZooKeeper 作为 LeaderElectionAgent 和存储引擎,当 Alive 状态的 Master 失败后会自动选举出新的主节点,并自动进行状态恢复。
事件总线
Master 在启动时会创建一个事件总线,并注册多个事件监听器,事件监听器可以方便地进行扩展,从而满足不同的需求。事件总线的核心是一个异步的事件分发机制,基于阻塞队列实现。当接收到新事件时,会将事件分派给事件监听器处理。每当 Master 接收到 Application 状态发生变更的消息时,就会将对应的事件放入事件总线,因而监听器可以及时获取到任务状态的变更事件。
RPC
RPC 概述
从上一节的介绍可以看出,作为一个分布式的系统,Master 和 Worker 之间存在大量的通信,这些不同的组件之间的通信正是通过 RPC 来实现的。
在 Aloha 中,RPC 模块不同于传统的 RPC 框架,不需要预先使用 IDL (Interface Description Language) 来定义客户端和服务端进行通信的数据结构、服务端提供的服务等,而是直接基于 Scala 的模式匹配来完成消息的识别和路由。之所以这样来实现,是因为在这里 RPC 的主要定位是作为内部组件之间通信的桥梁,无需考虑跨语言等特性。基于 Scala 的模式匹配进行路由降低了代码的复杂度,使用起来非常便捷。
我们先看一个简单的例子,来了解一下 RPC 的基本使用方法。其核心就在于 RpcEndpoint 的实现。
|
|
RpcEndpoint、 RpcEndpointRef 和 RpcEnv
从上面的例子很容易观察到,RpcEndpoint、 RpcEndpointRef 和 RpcEnv 是使用这个 RPC 框架的关键。如果你恰好知道一点 Actor 模型和 Akka 的基本概念,很容易就能把这三个抽象同 Akka 中的 Actor, ActorRef 和 ActorSystem 联系起来。事实上,Spark 内部的 RPC 最初正是基于 Akka 来实现的,后来虽然剥离了 Akka,但基本的设计理念却保留了下来。
简单地来说,RpcEndpoint 是一个能够接收消息并作出响应的服务。Master 和 Worker 实际上都是 RpcEndpoint。
RpcEndpoint 对接收的消息有两种方式,分别对应需要作出应答和不需要作出应答,即:
|
|
其中,RpcCallContext 用于向消息发送方作出应答,包括回复正常的响应以及错误的异常。通过 RpcCallContext 将业务逻辑和数据传输进行了解耦,服务方无需知道请求的发送方是来自本地还是来自远端。
RpcEndpoint 还包含了一系列生命周期相关的回调方法,如 onStart, onStop, onError, onConnected, onDisconnected, onNetworkError。
RpcEndpointRef 是对 RpcEndpoint 的引用,它是服务调用方发送请求的入口。通过获取 RpcEndpoint 对应的 RpcEndpointRef,就可以直接向 RpcEndpoint 发送请求。无论 RpcEndpoint 是在本地还是在远端,向 RpcEndpoint 发送消息的方法都是一致的。这也正是 RPC 存在的意义,即:执行一个远程服务提供的方法,就如同调用本地方法一样。
RpcEndpointRef 提供了如下几种请求的发送方式:
|
|
RpcEnv 是 RpcEndpoint 的运行时环境。一方面,它负责 RpcEndpoint 的注册,RpcEndpoint 生命周期的管理,以及根据 RpcEndpoint 的地址来获取对应 RpcEndpointRef;另一方面,它还负责请求的进一步封装,底层数据的网络传输,消息的路由等。
RpcEnv 有两种模式,一种是 Server 模式,一种是 Client 模式。在 Server 模式下,可以向RpcEnv 注册 RpcEndpoint,并且会注册一个特殊的 Endpoint,即 RpcEndpointVerifier,在获取 RpcEndpointRef 时,会通过 RpcEndpointVerifier 验证对应的 RpcEndpoint 是否存在。
RpcEnv 通过工厂模式来创建,底层具体的实现方案是可替换的,目前使用的是基于 Netty 实现的 NettyRpcEnv。
Dispatcher、Inbox 和 Outbox
在 NettyRpcEnv 内部,为了高效进行消息的路由与传递,使用了一种类似于 mailbox 的设计。
对于每一个 RpcEndpoint,都有一个关联的 Inbox,Inbox 内部有一个消息列表,这个消息列表中保存了这个 RpcEndpoint 收到的所有消息,包括需要应答的 RpcMessage,无需应答的 OneWayMessage, 以及各种和生命周期相关的状态消息,对于每一条消息,都会调用对应在 RpcEndpoint 内部定义的各种函数进行处理。而 Dispatcher 则充当了消息投递的角色。对于 NettyRpcEnv 接收到的所有消息, Dispatcher 都会根据指定的 Endpoint 标识找到对应的 Inbox,并将消息投递进去。此外,Dispatcher 内部启动了一个 MessageLoop,这个 MessaLoop 不断从阻塞队列中获取有新消息到达的 Endpoint,不断地消化新到达的这些消息。
和 Inbox 遥相呼应的是,在 NettyRpcEnv 内部维护了 RpcAddress 和 Outbox 的映射关系,每个远程 Endpoint 都对应一个 Outbox 。在通过 RpcEndpointRef 发送消息时, NettyRpcEnv 会根据 RpcEndpoint 的地址进行判断:如果是本地的 Endpoint, 则直接通过 Dispatcher进行消息投递;如果是远端的 Endpoint, 则将消息投递到对应的 Outbox 中。 Outbox 中也有一个待投递的消息列表,在首次向远端 Endpoint 投递消息时,会先建立网络连接,然后依次将消息发送出去。
网络传输
在 NettyRpcEnv 中,如何将请求发送给远端的 Endpoint,并收到远端 Endpoint 给出的回复,这就要要依赖于更底层的网络传输模块。网络传输模块,主要是对 Netty 的更进一步封装,其中关键的组件及功能如下:
TransportServer: 网络传输的服务端,当NettyRpcEnv以 Server 模式启动时就会创建一个TransportServer,等待客户端的连接请求TransportClient:网络传输的客户端,实际上就是对 channel 的进一步封装,一旦网络双方的请求建立成功,那么在 channel 的两端就各有一个TransportClient,从而可以以全双工的方式进行数据交换TransportClientFactory:创建TransportClient的工厂类,内部使用了连接池,可以复用已经建立的连接RpcHandler:负责对接收到的 RPC 请求消息进行处理,NettyRpcEnv就是在这个接口的方法中将消息交给Dispatcher进行投递RpcResponseCallback:RPC 请求响应的回调接口,NettyRpcEnv基于这个接口对接收到的数据进行反序列化TransportRequestHandler:对请求消息进行处理,主要是将消息转交给RpcHandler进行处理TransportResponseHandler:对响应消息进行处理,记录了每一条已发送的消息和与其关联的RpcResponseCallback,一旦收到响应,就调用对应的回调方法TransportChannelHandler:位于 channel pipeline 的尾端,根据消息类型将消息交给TransportRequestHandler或TransportResponseHandler进行处理TransportContext:用于创建TransportServer和TransportClientFactory,并初始化 Netty Channel 的 pipeline
其他的诸如引导服务端、引导客户端、消息的编解码等过程,都是使用 Netty 进行网络通信的惯常流程,这里不再详述。
小结
Aloha 是一个分布式调度框架 Aloha ,它的实现主要参考了 Spark。文中首先介绍了 Aloha 的使用场景和扩展方式,并采用自顶向下的方式重点介绍了 Aloha 的模块设计和实现方案。
Aloha 现已在 Github 开源,项目地址: https://github.com/jrthe42/aloha 。有关该项目的任何问题,欢迎各位通过 issue 进行交流。
-EOF-