Flink 源码阅读笔记(16)- Flink SQL 的元数据管理
文章目录
为了使用 SQL,一个首先需要解决的是元数据管理的问题。元数据的管理包括表的元数据和 UDF 的元数据,这使得完全使用 SQL 语句来构建实时任务成为可能。
Catalog 和 CatalogManager
在 1.9 版本发布之前,Flink SQL 完全借助于 Calcite 的 Schema 接口来管理注册的表,并且提供了 ExternalCatalog 接口,通过 TableDescriptor 定义外部系统数据的来源,从而访问到外部系统的数据。但是 ExternalCatalog 的定义不是非常完整,并且不太方便和 Hive 等已有的元数据管理进行集成。为此,Flink SQL 重构并提供了 Catalog 接口,Catalog 接口能够支持数据库、表、函数、甚至于分区等多种抽象。通过 CatalogManager,可以同时在一个会话中挂载多个 Catalog,从而访问到多个不同的外部系统。
|
|
目前 Flink SQL 提供了两个 Catalog 的具体实现,即 GenericInMemoryCatalog 和 HiveCatalog。GenericInMemoryCatalog 将所有元数据存储在内存中,而 HiveCatalog 则通过 HiveShim 连接 Hive Metastore 的实例,提供元数据持久化的能力。通过 HiveCatalog,可以访问到 Hive 中管理的所有表,从而在 Batch 模式下使用。另外,通过 HiveCatalog 也可以使用 Hive 中的定义的 UDF,Flink SQL 提供了对于 Hive UDF 的支持。
注册表
在 Catalog 中,每一张表对应的是一个 CatalogBaseTable 对象,CatalogBaseTable 及其子类的继承关系如下图:
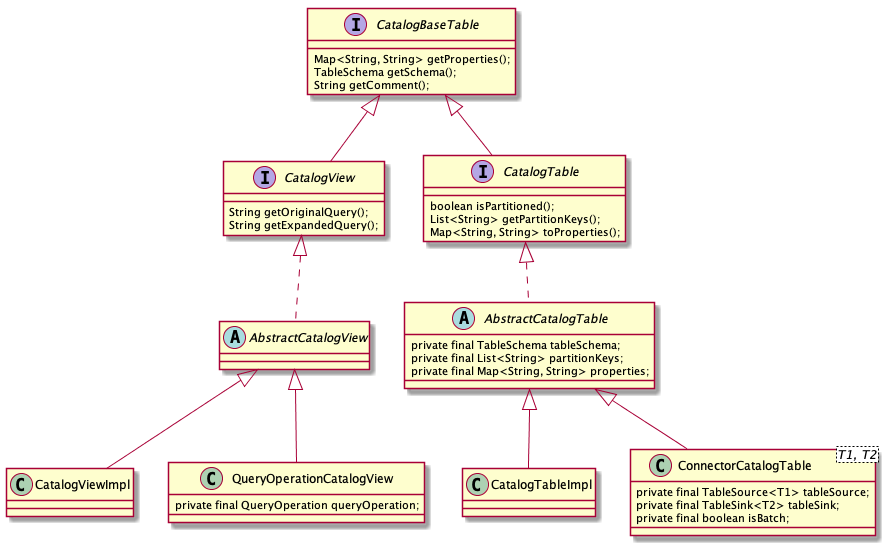
我们可以看到,Catalog 中管理的表大致可以分为两类,一类是表所对应的 CatalogTable,另一类则是视图所对应的 CatalogView。
在 Catalog 中注册的表,第一种是和 Catalog 固定在一起的,例如 HiveCatalog 直接从 Metastore 读取 Hive 中所有注册的表和视图,这种是由 Catalog 从外部存储中读取,一般无需用户手动注册,对应的实现一般为 CatalogTableImpl 和 CatalogViewImpl。
第二种向 Catalog 中注册表的方式是,用户提供 TableSource 和 TableSink 对象,并通过 TableEnvironment.registerTableSource() 和 TableEnvironment.registerTableSink() 方法进行注册。在这种情况下,TableSource 和 TableSink 会被封装在 ConnectorCatalogTable 中。
有的时候,我们并不希望直接创建 TableSource 和 TableSink 对象,例如在 SQL CLI 或其它环境中,这时候可以提供 TableDescriptor。TableDescriptor 描述了如何连接外部系统,并定义了表结构,解析方式等信息,Flink SQL 会通过 SPI 的方式自动加载匹配的 TableFactory,并创建 TableSource 和 TableSink 对象,之后再注册到 Catalog 中:
|
|
如果使用 Table API,我们可能需要将 DataStream 或者 DataSet 转化为 Table 并注册到 Catalog 中。如果使用 TableEnvironment.sqlQuery(),我们同样得到 Table 对象。我们在上一篇文章的 Table API 一节中曾经提过,在 Flink SQL 中,Table 对象的底层其实对应一个 QueryOperation。因此如果要将 Table 注册到 Catalog 中,其实是将 QueryOperation 封装为 QueryOperationCatalogView 注册到 Catalog 中。
此外,Flink SQL 提供了对 DDL 语句的支持,通过 CREATE TABLE 语句同样可以注册表到 Catalog 中。这里 FLink SQL 会解析 SQL 语句,从中提取出表结构、表属性等信息,封装在 CatalogTableImpl 中。
注册 UDF
用户自定义函数可以用来执行一些复杂的计算逻辑,这极大地增强了 Flink SQL 的扩展能力。用户可以提供 ScalarFunction,TableFunction, AggregateFunction,以及 TableAggregateTableFunction 的具体实现,并通过 TableEnvironment.registerFunction() 注册到 FunctionCatalog 中。
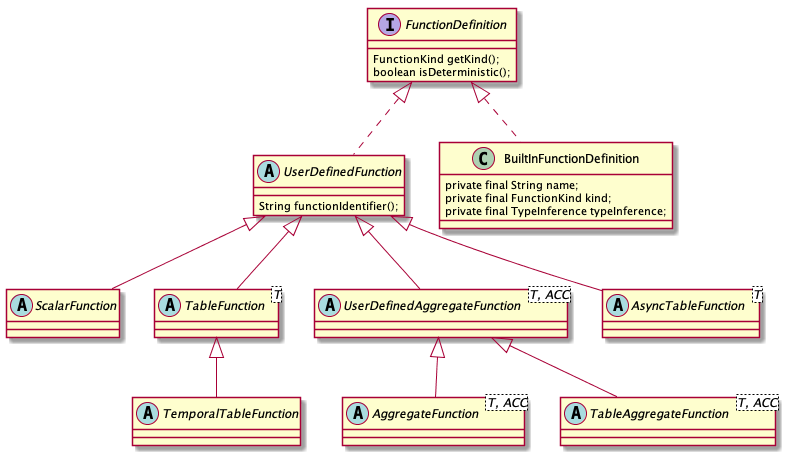
在目前的版本中,用户自行注册的 UDF 仍然是保存在内存中,即 FunctionCatalog 内部的一个 Map<String, FunctionDefinition> 对象中。后续应该会统一保存到 Catalog 中,可以通过 Catalog 进行持久化处理。
除了用户自行向 FunctionCatalog 注册的 UDF 以外,Catalog 自身也可能提供了一些函数,例如可以通过 HiveCatalog 复用 Hive 中的 UDF。通过 Catalog 查找到 CatalogFunction, CatalogFunction 中包含了 UDF 的一些基本属性,然后通过 FunctionDefinitionFactory 创建对应的 FunctionDefinition。具体可以参考 HiveTableFactory。
验证元数据
Flink SQL 依赖于 Calcite 来完成 SQL 语句的解析和逻辑计划的优化过程,因此需要将 Catalog 和 Calcite 使用的 Schema 桥接起来,这样 Calcite 才可以获取到由 Flink 管理的元数据。在 PlannerContext 中会负责初始化 Calcite 使用的 FrameworkConfig 和 RelOptCluster 等上下文环境。

通过 DatabaseCalciteSchema 可以获取到给定 database 下所有的表,因此可以验证 SQL 中使用的表是否存在,并且会转换成 Calcite 使用的 Table 对象(注意,这里说的 Table 是 Calcite 内部对表的抽象,注意和 Flink Table API 区分) 供 Calcite Planner 使用。
至于用户自定的函数,因为 Calcite 内部使用 SqlOperatorTable 来查找有效的操作符和函数,所以 Flink SQL 提供了 FunctionCatalogOperatorTable 将 FunctionCatalog 关联进来。如果是用户自定义的函数,则获取 FunctionDefinition 并生成 Calcite 使用的 SqlFunction 对象;如果是内置的函数,则在 FlinkSqlOperatorTable 中直接查找关联的 SqlFunction 对象。
如果使用 Table API,则函数调用会生成 LookupCallExpression,通过 LookupCallResolver 生成 UnresolvedCallExpression。LookupCallResolver 会通过 FunctionLookup (其实现即 FunctionCatalog) 查找对应的 FunctionDefinition (包括内置的函数,在 BuiltInFunctionDefinitions 中定义)。最终通过 ExpressionConverter 将 CallExpression 转换为 Calicte 内部的 RexNode,转换的过程中会根据 FunctionDefinition 生成 SqlFunction。
小结
对于数据平台而言,如果要将 SQL 投入生产环境使用,首先要解决的一个问题就是元数据的管理。在 Flink 1.9 之前,Flink SQL 并没有提供一个非常容易使用的元数据管理机制,而新引入 Catalog 接口在一定程度上使得外部系统和 Flink SQL 集成变得更为方便了。本文对 Flink SQL 中元数据管理机制的实现原理进行简单的介绍。
-EOF-
文章作者 jrthe42
原始链接 https://blog.jrwang.me/2019/2019-09-12-flink-sourcecode-sql-catalog/
上次更新 2019-10-09
许可协议 CC BY-NC-ND 4.0