Flink 的状态管理和检查点机制
文章目录
从状态说起
状态 (State) 是 Flink 程序中构建复杂逻辑的基本组件。流处理中的状态可以视作算子上的记忆能力,可以保留和已经处理完的输入相关的信息,并对后续输入的处理造成影响。与之相反,流处理中的无状态操作只会考虑到当前处理的元素,不会受到处理完毕的元素的影响,也不会影响到后续待处理的元素。
简单来说,假定一个 source stream 中的事件消息都符合 e = {event_id:int, event_value:int} 这种模式。如果我们的目标是提取出每一条消息中的 event_value, 那么一个很简单的 map 操作就可以完成,这个 map 操作就是无状态的。但是,如果我们只想要输出那些 event_value 值比之前处理过的值都要高的那些消息,我们要如何实现呢?显然,我们需要记住已经处理过的消息中最大的 event_value,这就是有状态的操作。
Flink 中的状态
在 Flink 中,状态分为两种,即 Keyed State 和 Operator State。Operator State 绑定到算子的每一个并行实例(sub-task) 中,而 Keyed State 总是和 Key 相关联,只能在 KeyedStream 的函数或算子中使用。 因为 Flink 中的 keyBy 操作保证了每一个键相关联的所有消息都会送给下游算子的同一个并行实例处理,因此 Keyed State 也可以看作是 Operator State 的一种分区(partitioned)形式,每一个键都关联一个状态分片(state-partition)。
从另一个维度来看, Flink 中的状态还可以分为 Managed State 和 Raw State。Managed State 是指由 Flink 的运行时环境来管理状态,而 Raw State 则是由算子自行管理状态,Raw State 的数据结构对 Flink 是透明的。 Flink 的建议是尽量使用 Managed State, 这样 Flink 可以在并行度改变等情况下重新分布状态,并且可以更好地进行内存管理。
Flink 中提供了三种形式的存储后端用来存储状态,分别是 MemoryStateBackend, FsStateBackend 和 RocksDBStateBackend。MemoryStateBackend 将状态存储在堆内存中,是默认使用的存储后端,由于存储容量限制,通常只在调试开发中使用。FsStateBackend 会将状态存储到一个持久化的存储中,如 HDFS,只在 JobManager 的内存中存储一些 metadata。RocksDBStateBackend 将状态存储在RockDB中,并且支持增量快照。在最新版的 Flink 中,这三种形式的存储后端都支持异步快照模式。
在 Flink 中使用状态
在 Flink 中,状态的基本类型包括 ValueState<T>, ListState<T>, ReducingState<T>, MapState<T> (FoldState<T> 已经被移除)。这些状态有对应的更新和清除的方法,具体参见 API 文档,不再赘述。
要获取状态,首先需要定义状态描述符(StateDescriptor)。状态描述符状态的名字(保证唯一性),状态的类型,以及部分状态需要的自定义函数。根据想要获取的状态的不同,状态描述符也分为 ValueStateDescriptor, ListStateDescriptor, ReducingStateDescriptor, MapStateDescriptor。
CheckpointedFunction 接口
要在自定义的函数或算子中使用状态,可以实现 CheckpointedFunction 接口,这是一个比较通用的接口,既可以管理 Operator State,也可以管理 Keyed State,灵活性比较强。它要求实现如下两个方法:
|
|
例如:
|
|
ListCheckpointed 接口
使用 Operator State 的另一种更方便的形式是实现 ListCheckpointed 接口。
|
|
RuntimeContext
对于 Keyed State,通常都是通过 RuntimeContext 实例来获取,这通常需要在 rich functions 中才可以做到。 RuntimeContext 提供的获取状态的方法包括:
|
|
要记住,使用 Keyed State 一定要在 Keyed Stream 上进行操作,并且由于状态总是和 key 相关联的,同一个并行算子实例中不同消息获取到的状态并不一定相同。
|
|
检查点 (Checkpint)
由于 Flink 中的操作可以是有状态的,在作业失败后进行恢复的时候需要正确地还原算子的状态,这就需要依赖于 Flink 的检查点(快照)机制。实际上不仅仅是错误恢复,有时我们需要对作业运行时的并行度进行调整(缩放,Scale)这也要依赖于检查点。
在进行快照的时候,需要保存算子的状态,这既包括用户自定的状态,也包括系统状态(比如数据缓冲区 window buffer)等。检查点机制还需要依赖于 1)支持数据重播的数据源 2)状态的持久存储终端。
Flink 实现了一个轻量级的分布式快照机制,其核心点在于 Barrier。 Coordinator 在需要触发检查点的时候要求数据源注入向数据流中注入 barrie, barrier 和正常的数据流中的消息一起向前流动,相当于将数据流中的消息切分到了不同的检查点中。当一个 operator 从它所有的 input channel 中都收到了 barrier,则会触发当前 operator 的快照操作,并向其下游 channel 中发射 barrier。当所有的 sink 都反馈收到了 barrier 后,则当前检查点创建完毕。

完整的检查点创建流程如下:

对齐操作
一个关键的问题在于,一些 operator 拥有多个 input channel,它往往不会同时从这些 channel 中接收到 barrier。如果 Operator 继续处理 barrier 先到达的 channel 中的消息,那么在所有 channel 的 barrier 都到达时,operator 就会处于一种混杂的状态。在这种情况下,Flink 采用对齐操作来保证 Exactly Once 特性。Operator 会阻塞 barrier 先到达的 channel,通常是将其流入的消息放入缓冲区中,待收到所有 input channel 的 barrier 后,进行快照操作,释放被阻塞的 channel,并向下游发射 barrier。

对齐操作会对流处理造成延时,但通常不会特别明显。如果应用对一致性要求比较宽泛的话,那么也可以选择跳过对齐操作。这意味着快照中会包含一些属于下一个检查点的数据,这样就不能保证 Exactly Once 特性,而只能降级为 *At Least Once*。
异步快照
前述的检查点创建流程中,在 operator 进行快照操作时,不再处理数据流中的消息。这种同步的方式会在每一次进行快照操作的时候引入延时。实际上,Flink 也支持采用异步的方式创建快照,这就要求 operator 在触发快照操作的时候创建一个不受后续操作影响的状态对象,通常选用 copy-on-write 的数据结构。Flink 中基于 RocketDB 的状态存储后端就可以支持异步操作。
环形数据流的快照
对于环形数据流图创建快照,在 IterationHead 中会进行一个特殊的操作,在 IterationHead 收到来自 IterationTail 的 marker 后,将当前检查点范围内流过的所有记录都保存在快照中。其它的节点进行的快照和无环情况下一致。详细的介绍可参考 Flink 团队今年在 VLDB Endowment 发表的论文。
保存点
所谓的保存点,其实是用户手动触发的一种特殊的检查点。其本质就是检查点,但它相比检查点有两点不同:1)用户自行触发 2)当有新的已完成的检查点产生的时候,不会自动失效。
可查询状态(Queryable State)
Flink 自1.2起新增了一个 Queryable State 特性,允许从 Flink 系统外直接查询作业流水中的状态。这主要是来自于两方面的诉求:1)很多应用都有直接获取应用实时状态的需求,2)将状态频繁写入外部系统中可能是应用的瓶颈。
有两种方式来使用 Queryable State :
QueryableStateStream, 将KeyedStream转换为QueryableStateStream,类似于 Sink,后续不能进行任何转换操作StateDescriptor#setQueryable(String queryableStateName),将 Keyed State 设置为可查询的 (不支持 Operator State)
外部应用在查询 Flink 作业内部状态的时候要使用 QueryableStateClient, 提交异步查询请求来获取状态。
下面的两张图大致给出了 Queryable State 的工作机制:
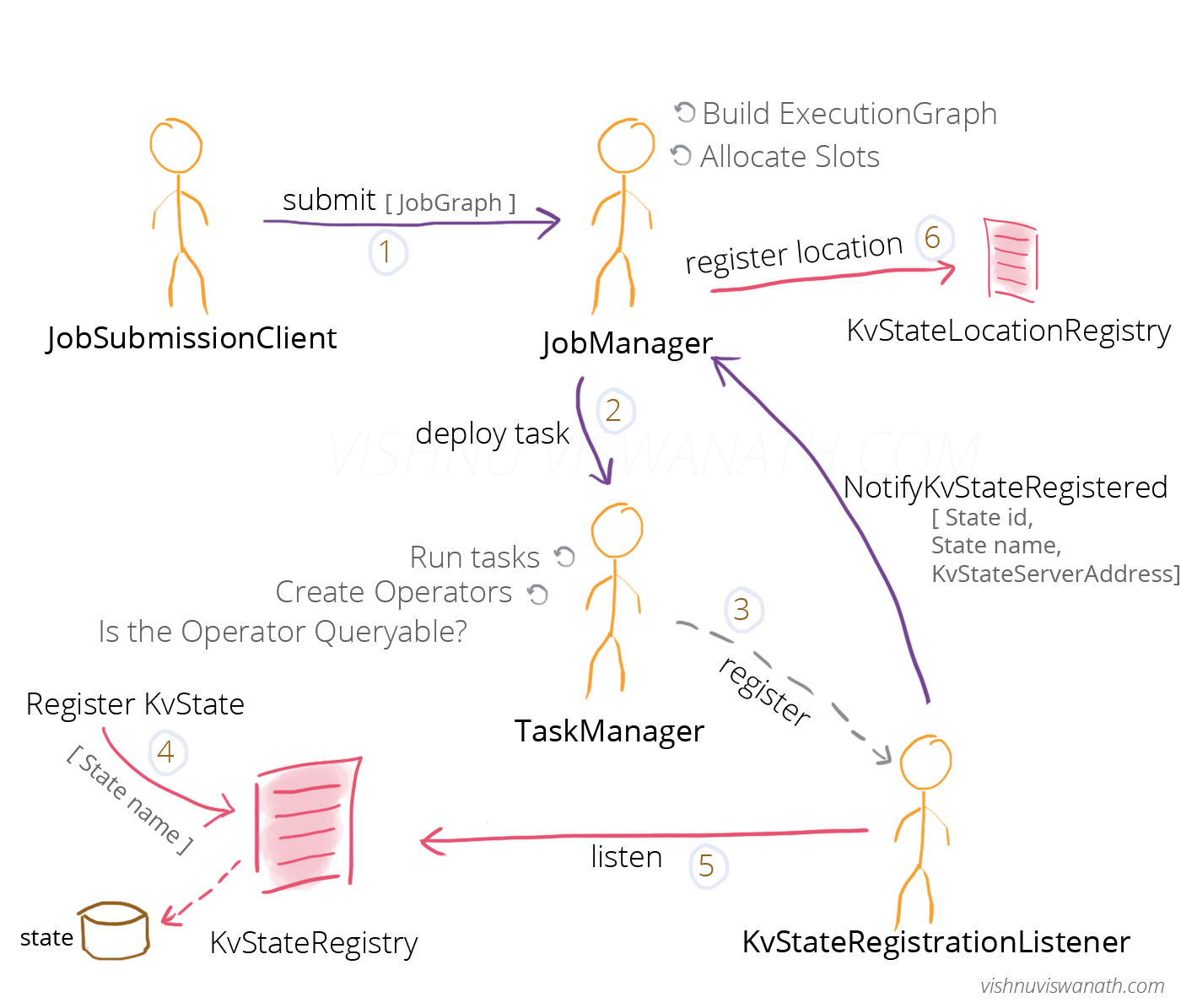

目前还存在的一些局限:
- 只能支持 Keyed Operator
- 对状态大小是否有限制(不支持 ListState)
- 作业失败后如何保证可用性
- Clent API 的易用性
参考
- Working with State
- A Deep Dive into Rescalable State in Apache Flink
- Queryable States in ApacheFlink - How it works
-EOF-
文章作者 jrthe42
原始链接 https://blog.jrwang.me/2017/flink-state-checkpoint/
上次更新 2019-09-12
许可协议 CC BY-NC-ND 4.0