记一次使用 PutSortReducer 时 OOM 错误的排查过程
文章目录
之前写过一篇文章介绍如何使用 Bulk Load 的方式向 HBase 中批量导入数据。前两天在运行导入任务时总是会有一个 Reduce 出现 GC overhead limit exceeded 的错误从而导致任务失败,这一度让我非常困惑。谷歌搜索了一圈也没有发现可行的解决方案,无奈只能自己解决了。经过仔细排查,最终定位了出错的原因,这里做一个简单的记录。
GC 日志及堆转储快照的分析
目前给执行 Reduce 任务的 Container 配置的堆内存是 756M。为了搜集 GC 日志并在发生 Out of Memory 时将堆内存文件保存下来,需要调整一下配置,将 mapreduce.reduce.java.opts 这一项调整为 -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/@taskid@.hprof。开启 GC 日志记录,并在发生 OOM 时将堆内存转存到 /tmp 文件夹下。其中 @taskid@ 会被替换为任务的 Id。
GC 日志可在相应任务的标准输出中查看。要查看 Yarn 任务的日志信息,需要开启日志聚合功能,可以使用 yarn logs -applicationId application_1391047358335_0041 -containerId container_1391047358335_0041_01_000002 -nodeAddress nmhost:8041 命令查看,也可在 JobHistory 的 WebUI 中查看,这里不多做介绍。

从 GC 日志中可以看到,在多次发生 Full GC (Stop-The-World) 后,堆中已使用的内存始终接近于堆的内存总量,因而出现了 OOM 的错误。此时,程序应该仍在申请新的内存空间,然而却没有足够的空间可以分配了。
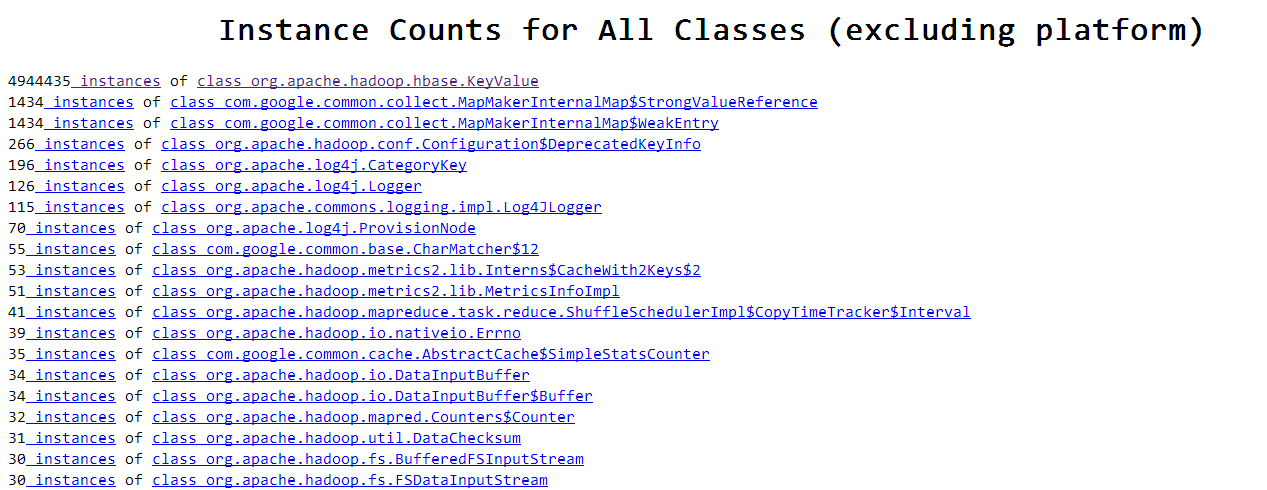

因为配置了堆内存转储,这里直接通过 jhat 来分析生成的堆转储快照。从各类对象占用的内存来看,此时堆中存在大量的 TreeMap$Entry 和 KeyValue 的实例。这些实例到底是怎么出现的呢?要弄清楚这一点,我们还是要结合具体的代码来看一下。
PutSortReducer 源码分析
我们在使用 Bulk Load 和 MapReduce 的方式向 HBase 中导入数据时,使用自定义的 Mapper 进行数据转换,Reducer 则是使用 HBase 的 PutSortReducer 类。PutSortReducer 类的源代码可以在开源社区找到,其实内部的逻辑还挺简单的,我们来分析一下:
PutSortReducer 的主要作用是对从 Map 阶段获取的所有 Put 进行排序,并按序写入输出流中,最终写入 HFile 文件是由 HFileOutputFormat2 完成的。每处理一行(Row)会调用一次 reduce 方法,该行所有的 put 都会通过迭代对象传入。
|
|
现在我们知道 KeyValue 和 HashMap$Entry 是从哪里来的了。在 Reduce 过程中, PutSortReducer 类对每一行(Row)会进行一次 Reduce 操作,在这一次操作中会处理该行的所有数据。Reduce 内部排序是通过 TreeSet(红黑树结构)实现的,为了处理同一行记录非常多的情况,PutSortReducer 使用了一个刷写阈值,并维持一个当前已经放入树中的 KeyValue 的总内存大小,当大小超过刷写阈值时就会进行一次强制的写入操作。不过在 PutSortReducer 中默认的阈值是 1 GB。
在我们的表结构设计中,有的表会使用多 Version 的方式存储,将 Version 作为其中的一个维度,对于一些特殊的情况(这里不便描述)会出现一行中存在大量 Column (不同的 Version) 的情况,这里就很不幸地遇到了。因为 KeyValue 的内存总量仍然没有达到刷写阈值(默认 1GB),然而此时堆中已经没有足够的内存了。
解决方法
解决方法其实很简单,可以将 Reduce 的内存总量及对内存调整的更大一些,不过更好的方法是对 PutSortReducer 中的刷写阈值进行调整。在 Reduce 中会读取 putsortreducer.row.threshold 属性,没有则使用默认值,也就是 1GB,因而我们可以在任务提交前设置该阈值。
|
|
将该值调整为 512 MB后重新运行,成功完成任务。当然,这个阈值的设置可以依据 JVM 虚拟机的堆内存进行调整,建议设置保守一点,以保证任务正常执行下去。
因为每次强制刷写后都会生成一个 StoreFile,在极端的情况下生成的文件数量可能会很多,在使用 bulk load 载入的时候可能会出错 ERROR mapreduce.LoadIncrementalHFiles: Trying to load more than 32 hfiles to family f of region ... (没错,我也遇到了T@T.),可以修改一下这个属性 hbase.mapreduce.bulkload.max.hfiles.perRegion.perFamily,默认是 32。
小结
这篇文章主要是对使用 PutSortReducer 中遇到的问题及解决过程做一个总结。PutSortReducer 在极端情况下可能会造成内存溢出的问题,主要是内部使用的内存阈值和当前分配的堆内存不匹配造成的,在使用的时候按需调整该阈值即可。
-EOF-
文章作者 jrthe42
原始链接 https://blog.jrwang.me/2016/gc-overhead-limit-in-putsortreducer/
上次更新 2019-09-12
许可协议 CC BY-NC-ND 4.0